






Искусственный интеллект на стероидах
2024-03-19

Что такое тензорные ядра и какова роль облачных сервисов, предлагающих доступ к современным GPU.
Технологии искусственного интеллекта (AI) и машинного обучения (ML) развиваются уже десятилетия, однако лишь в последние несколько лет они совершили гигантский скачок вперед. Этому в значительной степени способствовала и новая аппаратная база, например доступность мощных GPU с тензорными ядрами. Такие устройства могут предоставить большое преимущество в процессе решения специализированных задач, таких как обучение или использование нейросетей, и сегодня они уже доступны как сервис в облаках украинских операторов.
Что привело к появлению Tensor Processing Unit (TPU)
В современном ИТ-мире благодаря стремительному развитию технологий ситуация меняется очень быстро и на передний план выходит умение компаний своевременно реагировать на ситуацию, используя новую реальность в свою пользу. Недавний скачок в сфере AI/ML привел к лавинообразному росту количества новых продуктов, сервисов, а главное компаний, для которых искусственный интеллект, машинное обучение, нейросети и другие связанные с этим вещи являются основой бизнеса. Ежедневно появляются сотни и тысячи стартапов, которые используют AI/ML для создания чего-то нового, и в повседневной жизни подобные технологии окружают нас постоянно.
Но для эффективных вычислений AI/ML нужны огромные ресурсы, и до недавнего времени это была серьезная проблема. Традиционные процессоры (CPU) работают слишком медленно для таких задач, где краеугольным камнем выступает параллельная обработка и операции над числовыми матрицами. Да, современные CPU содержат десятки ядер , но этого все равно недостаточно, потому что вычисления с их применением обходятся дорого, что является естественной расплатой за универсальность
В начале 2000-х производители видеокарт пришли к выводу, что процесс обработки графики можно разбить на множество небольших подзадач, выполняемых параллельно. Причем решать эти подзадачи можно на специализированных ядрах, работающих с шейдерами (инструкциями, указывающими, как правильно отображать и трансформировать объекты на изображениях). Такие ядра имеют достаточно ограниченное применение, но хорошо выполняют операции над числами с плавающей запятой – то, что нужно для графики. Тем более что благодаря их относительной простоте и низкому энергопотреблению на одной видеокарте таких ядер может быть сотни и даже тысячи.
Результатом объединения в одном устройстве универсальных процессоров, специализированных шейдерных ядер и ряда других технологий стало появление GPU (Graphics Processing Unit), которые начали применять не только для рендеринга изображений или работы с видео. По сути GPU стали универсальным ответом везде, где возможна массовая параллельная обработка процессов. Их стали использовать в научных и инженерных задачах, суперкомпьютерных вычислениях, при анализе больших массивов данных и, в частности, для AI/ML.
В последнем случае, хотя скорость работы GPU была высокой, оказалось, что большие модели машинного обучения обсчитываются все же недопустимо долго (если говорить о массовом применении). Что ж, есть проблема – будет найдено решение. Ответом на вызов стало появление в 2017 году нового типа GPU на базе архитектуры Volta, разработанной NVIDIA. Ключевым моментом здесь стало то, что вдобавок к шейдерным появились еще и ядра нового типа – тензорные (Tensor Core) специально созданные для выполнения определенных типов операций. Это явилось началом нового толчка для ИТ-эволюции, последствия которого мы сейчас и наблюдаем.
Отметим, что специальные тензорные модули (Tensor Processing Unit, TPU) еще в 2016 году представила компания Google, но они использовались исключительно для внутренних задач и не появлялись на массовом рынке.
Что такое тензорные ядра?
Что такое “тензорные ядра” и почему они хорошо подходят для задач AI/ML? Начнем с того, что "тензор" это определенный тип математического объекта, обычно выглядящий как массив чисел определенной размерности. Например, числовая матрица – это тензор с размерностью 2 (а "обычное", скалярное, число это тоже тензор, но с размерностью 0). Есть и другие размерности. Нам в этом случае важно, что основная операция, в которой тензорные ядра обеспечивают преимущество – это перемножение и сборка числовых матриц.
С такой задачей может справиться и обычный процессор (собственно, раньше так и было), но для этого ему придется совершить большое количество действий, использовать множество регистров и нагрузить кэш-память множеством операций чтения/записи. Как следствие, для эффективной работы с тензорами строились огромные кластеры, содержащие сотни и тысячи CPU.
Вместе с тем, тензорный процессор благодаря возможности одновременного выполнения нескольких вычислений осуществит все необходимые операции по перемножению матриц за один такт. К тому же в составе одного GPU могут работать сотни тензорных ядер, а значит, многие типовые операции выполняются параллельно, повышая производительность.
«Тензорное ядро – очень узкоспециализированное устройство, все, что оно умеет – перемножить две матрицы 4х4 и сложить с третьей матрицей. Эта задача требует выполнения 128 отдельных операций – 64 умножения и 64 сложения. Магия в том, что тензорное ядро делает все это за один такт, а типичный тензорный акселератор содержит сотни тензорных ядер, что позволяет ему работать с этим типом нагрузки в сотни и тысячи раз быстрее, чем процессор общего назначения» - Геннадий Карпов, директор по технологиям De Novo.
Работа с числовыми матрицами повсеместно встречается в процессе решения сложных научных, инженерных, логистических задач, а также, что важно в контексте нашей статьи, в машинном обучении (ML). Основой ML являются так называемые нейросети – математические модели, представляющие собой огромные массивы данных из "узлов" и "соединений". Каждый узел имеет определенное значение, каждое соединение имеет "вес" – коэффициент, задающий его важность.
Для анализа поведения модели необходимо каждое значение узла нейросети умножить на все возможные веса соединений. Фактически эта задача сводится к перемножению матриц, а здесь тензорные процессоры демонстрируют ошеломительные результаты. Поэтому сегодня без них не обходится фактически ни одна серьезная задача в сфере AI/ML и, соответственно, все топовые GPU содержат тензорные ядра для поддержки вычислений.
Преимущества, недостатки и основное применение тензорных ядер
Среди ключевых преимуществ GPU на тензорных ядрах можно назвать высокую, недостижимую для других технологий, производительность, особенно на специфических задачах, связанных с алгоритмами искусственного интеллекта, машинного или глубокого обучения (Deep Learning). Большим плюсом является энергоэффективность. Номинально, такие GPU потребляют сотни ватт, иногда до 700 Вт и более, но удельный расход электроэнергии — в пересчете на количество выполненных операций — оказывается минимальным. Также ускорители относительно легко совмещаются в кластере с возможностью почти безграничного масштабирования.
Тензорные ядра, хотя и не в полной мере универсальны, но, как мы отметили выше, обеспечивают существенное преимущество в ряде специализированных задач, требующих огромных вычислительных нагрузок. Особенно эффективны они там, где задачи могут быть распараллелены и оптимизированы для тензорных вычислений.
Одним из типичных применений тензорных ядер является тренировка алгоритмов AI, связанных, например, с обработкой естественного языка (NLP). При использовании обычных GPU на шейдерных ядрах процесс может занять недели и месяцы, а благодаря тензорным ядрам его нередко можно сократить до нескольких дней. Кроме того, обеспечивается более эффективная и быстрая работа уже обученной нейросети (инференс), поскольку тут важна высокая производительность и пропускная способность в сочетании с низкими задержками в процессе обработки и передачи данных.
Огромный прирост в производительности дают тензорные ядра и при решении задач в рамках высокопроизводительных вычислений (High Performance Computing, HPC). Это могут быть научные или сложные инженерные расчеты, моделирование, построение прогнозов. Также эффективны тензорные GPU в проектах, связанных с виртуальной и дополненной реальностью, 3D-рендерингом, разработкой видеоигр.
Без тензорных ядер не удалось бы добиться решительного прогресса в таких областях, как быстрое и точное распознавание (идентификация) лиц на изображениях и видео, автономные автомобили, машинный перевод, разработка лекарств и исследования в области ДНК. Сфера применения технологии расширяется каждый день.
Однако очевидным недостаткам ускорителей на тензорных ядрах остается их высокая цена, которая для топовых моделей может достигать десятков тысяч долларов. Но даже с учетом этого фактора спрос на них настолько велик, что с момента оплаты до фактической поставки заказчику может пройти до года. И это только самая карта, к которой еще нужна соответствующая инфраструктура. Итоговая стоимость рабочего решения может легко достичь $100 тыс. и более.
Поэтому, учитывая потребность в вычислительных мощностях для задач AI/ML с одной стороны, и высокую стоимость соответствующих аппаратных компонентов с другой – неудивительно, что в мире быстро растет спрос на облачные сервисы, предлагающие моментальный доступ к современным GPU на тензорных ядрах по модели «как сервис». Подобные услуги уже доступны и от украинских операторов.
Тензорные ядра украинских операторов
Украинские облачные операторы вкладывают немалые средства в развитие своих ИТ-инфраструктур и вообще не отстают от глобальных тенденций. Чтобы получить доступ к тензорным акселераторам, не обязательно переносить свои данные за границу — соответствующие мощности есть сегодня и внутри нашей страны. На начало 2024 года украинские операторы предлагали доступ к GPU с тензорными ядрами на основе карт NVIDIA A40, A100 и H100. Каждая из этих моделей имеет свои особенности, преимущества и области применения. Чтобы лучше разобраться в вопросе, рассмотрим каждую модель подробнее.
Начнем с серии "А". Модели А40 и А100 объединяет общая процессорная архитектура – Ampere. Это архитектура третьего поколения, представленная NVIDIA в 2020 году. Для ее реализации использовались самые современные на тот момент техпроцессы — 7 и 8 нм, что позволило разместить на чипе 54 млрд транзисторов. Также здесь была реализована поддержка фирменной, высокоскоростной технологии интерконнекта – NVLink третьего поколения, которая обеспечивает скорость обмена данными между картами, гораздо более высокую, чем в случае самой свежей версии PCIe.
Из интересных технологий еще стоит упомянуть NVIDIA Multi-Instance GPU. MIG позволяет разделить один физический ускоритель на несколько полностью изолированных сред (инстансов) — каждая с собственной памятью, кэшем и вычислительными ядрами. Такая функциональность может быть альтернативой гипервизорной виртуализации GPU. По сравнению с архитектурой предыдущего, второго поколения (называется Turing , появилась в 2018 году), модели на основе Ampere используют более быструю оперативную память, а также технологии повышенной надежности для обеспечения защиты и конфиденциальности данных.
Здесь мы кратко рассмотрим две модели GPU серии A (сокращение от Ampere) – А40 и А100, потому что именно они наряду с некоторыми другими моделями сегодня используются облачными украинскими операторами. При этом в портфолио NVIDIA имеется десять основных моделей ускорителей вычислений с тензорными ядрами, а также их разнообразные вариации.
Как можно заключить из названия, А40 является "младшим" вариантом по отношению к А100 (рис. 1). Некоторые сравнительные характеристики, дающие представление о разнице между моделями, представлены в таблице .
Табл. 1. Сравнение отдельных моделей GPU NVIDIA с тензорными ядрами
| Модель | A40 | A100 | H100 |
|---|---|---|---|
| Архитектура | Ampere | Ampere | Hooper |
| Техпроцесс, нм | 8 | 7 | 4 |
| Шейдерные ядра (CUDA), ед. | 10752 | 6912 | 16896 |
| Тензорные ядра, ед. | 336 | 432 | 528 |
| Объем оперативной памяти, ГБ | 48 | 40/80 | 80/96 |
| Пропускная способность памяти, ТБ/с | 0,7 | 2 | 3,35 |
| Интерконнект, Гбит/с | 112,5 | 600 | 900 |
| Производительность FP32* (non-Tensor), TFLOPS | 37,4 | 19,5 | 67 |
| Производительность TF32 (Tensor), TFLOPS | 149,6 | 312 | 989 |
| Основные задачи | VDI, облачные игры, анализ данных, небольшие модели AI/ML | Высокопроизводительные вычисления, большие модели AI/ML, анализ огромных массивов данных | Высокопроизводительные вычисления, обучение AI/ML для очень сложных моделей и наборов данных, анализ огромных массивов данных, крупномасштабные научные симуляции. |
| Ориентировочная цена, $ тыс. | 6 | 20 | 38 |
*Одинарная точность вычислений с плавающей запятой
Объективно, А40 — это мощная, современная и производительная карта, которая вместе с тем уступает А100 почти по всем основным характеристикам, кроме разве что, количества обычных шейдерных ядер и, соответственно, может в некоторых случаях иметь более высокую производительность на задачах, не требующих тензорных операций. Также А40 стоит в разы дешевле. Когда речь заходит о сфере искусственного интеллекта и машинного обучения, то здесь А100 уверенно обходит младшего брата. Каждая модель имеет свою сферу применения.

Рис. 1. Внутенний вид GPU NVIDIA A100
К типовым задачам для А40 (рис. 2) можно отнести развертывание инфраструктур виртуальных рабочих столов (VDI), облачные игры, анализ бизнес-данных, НРС-нагрузку невысокой интенсивности, а также работу с небольшими моделями AI и ML. Для работы с большими наборами данных или сложными моделями AI/ML мощности не хватит.

Рис. 2. GPU NVIDIA A40 в корпусе
В свою очередь, А100 была специально разработана для высокопроизводительных вычислений, работы с большими моделями искусственного интеллекта и машинного обучения, а также анализа огромных массивов данных. Модель имеет больше тензорных ядер, оперативной памяти (которая к тому же работает гораздо быстрее), более продуктивный интерконнект и ряд других важных преимуществ по сравнению с А40 (рис. 3).
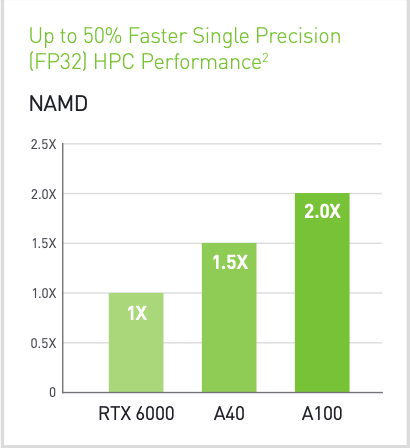
Рис. 3. Сравнение производительности GPU с тензорными ядрами A40 и A100 на HPC-задачах. Источник: NVIDIA.
С другой стороны, все это влияет не только на цену, но и на энергопотребление устройства, налагая дополнительные требования к размещению и поддержке.
Технологии не стоят на месте, в 2023 году NVIDIA представила индустрии новую архитектуру – Hooper и GPU серии "Н" на ее основе. Здесь уже используется техпроцесс 4 нм, что позволило разместить 80 млрд транзисторов и существенно увеличить количество ядер . В сочетании с новыми технологиями (такими как Transformer Engine) это привело к росту производительности GPU в десятки раз на некоторых задачах AI/ML по сравнению с моделями предыдущих поколений.
Скорость интерконнекта благодаря технологии NVLink четвертого поколения была увеличена в разы – до 900 Гбайт/с в обоих направлениях (это в семь раз больше, чем пропускная способность шины PCIe Gen5). Кроме того, NVLink теперь поддерживает внутрисетевые вычисления (SHARP) и на задачах ИИ способна поддерживать вычисление экзафлопного уровня. Технология MIG второго поколения обеспечивает поддержку семи изолированных и защищенных инстансов.
Дополнительно Hooper содержит инструкции динамического программирования DPX, которые, если не вдаваться в подробности, позволяют эффективно и быстро решать сложные рекурсивные задачи путем их разбиения на более простые подзадачи. Как следствие, например, сложные логистические задачи решаются в разы быстрее, чем если бы использовались GPU на Ampere.
Самой мощной GPU NVIDIA на основе архитектуры Hooper, по состоянию на 1 квартал 2024 года, является модель Н100 (рис. 4). У нее больше ядер (как шейдерных , так и тензорных), оперативной памяти и вычислительной мощности, чем у любой системы серии А.

Рис. 4. Внутренний вий GPU NVIDIA Н100
Быстрее работает оперативная память, увеличена пропускная способность интерконнекта , заметно возросла производительность на любых задачах. Н100 отлично справляется с интенсивными вычислениями, обучением больших и сложных моделей AI/ML, крупномасштабными научными симуляциями, обработкой больших массивов данных и т.д
Одним из важных технологических новшеств, появившихся в рамках архитектуры Hooper, является поддержка двух новых форматов точности вычислений с плавающей запятой – FP8 и FT32.
Напомним, не прибегая к подробностям, что сегодня существует целый ряд подобных форматов. Наиболее ресурсоемкий – FP64 или вычисление двойной точности, он используется в научных задачах, при сложном проектировании и почти не востребован в других областях. Самый распространенный формат – FP32, обеспечивающий одиночную точность вычислений. При этом на задачах AI/ML, например, при обучении нейросетей, точность вычислений далеко не всегда является критически важным параметром, в отличие от времени выполнения задачи, поэтому здесь больше распространен формат FP16 (с половинной точностью).
В NVIDIA пошли еще дальше, применив в новых GPU формат FP8, требующий еще меньше вычислительных ресурсов, чем даже FP16 и, соответственно, сокращающий время обработки специализированных задач. По данным NVIDIA, вычисления в формате FP8 на архитектуре Hopper выполняются в 6 раз быстрее, чем аналогичные задания в формате FP16 на Ampere . Более того, тензорные ядра Hopper способны комбинировать форматы FP8 и FP16, что позволяет существенно ускорить процесс обучения некоторых типов нейронных сетей без потери точности.
Также добавлен новый фирменный формат FT32, являющийся чем-то средним между привычными вычислениями одинарной и половинной точности. По данным NVIDIA, это дает точность близкую к FP32 и скорость FP16. Благодаря этому обработка задач AI/ML происходит в три раза быстрее, по сравнению с тензорными ядрами Ampere .
Но, опять-таки, следствием повышенной производительности и эффективности является высокая цена устройства. К тому же из-за роста рабочих нагрузок для AI/ML, спрос на H100 сегодня ощутимо превышает предложение. В итоге, цена одного лишь ускорителя легко может превысить $40 тыс, так что покупка такого GPU далеко не всем по карману.
Но доступ к этому акселератору можно получить из облака De Novo, воспользовавшись возможностями новых сервисов Hosted Tensor Infrastructure (HTI) и Tensor Cloud на базе частного и коллективного облака соответственно. Либо же в составе первой национальной AI/ML-платформы ML Cloud. Сегодня De Novo - это единственный украинский облачный оператор, предлагающий доступ к самым мощным GPU NVIDIA H100, физически расположенным внутри страны.
Акселераторы на тензорных ядрах являются мощными инструментами для работы с алгоритмами машинного обучения, искусственного интеллекта и другими задачами, требующими высокой производительности. Но перед использованием таких GPU необходимо тщательно оценить будущие задачи и выбрать систему с соответствующими характеристиками.
Какое решение с тензорными ядрами подойдет именно вам — легко проверить на практике. Достаточно обратиться к специалистам De Novo , которые предоставят развернутую консультацию по любым техническим вопросам. Затем можно получить тестовый доступ к необходимому облачному сервису или даже запустить собственный пилотный проект, после чего, если все устраивает, перейти к полноценной эксплуатации, получая все преимущества передовых технологий.