





Платформа AI/ML для запуска, обучения и инференса моделей AI/ML
Готовая среда для работы с машинным обучением — без лишних затрат времени на настройку инфраструктуры, развернутая в облаке с NVIDIA GPU.
ML Cloud объединяет интегрированный, предварительно сконфигурированный и самодостаточный пакет «best of breed» з open source MLOps-инструментов и акселераторы NVIDIA H200 NVL / H100 / A100 NVL / L40s / L4.
Готовая к использованию рабочая среда ML-инженера – это значительное снижение порога входа в мир AI/ML. Новейшие тензорные акселераторы NVIDIA обеспечивают недосягаемую для других технологий производительность на задачах машинного обучения и продуктивного инференса.
Просто заходите и начинайте обучать, развертывать или выполнять инференс моделей — без лишних хлопот.

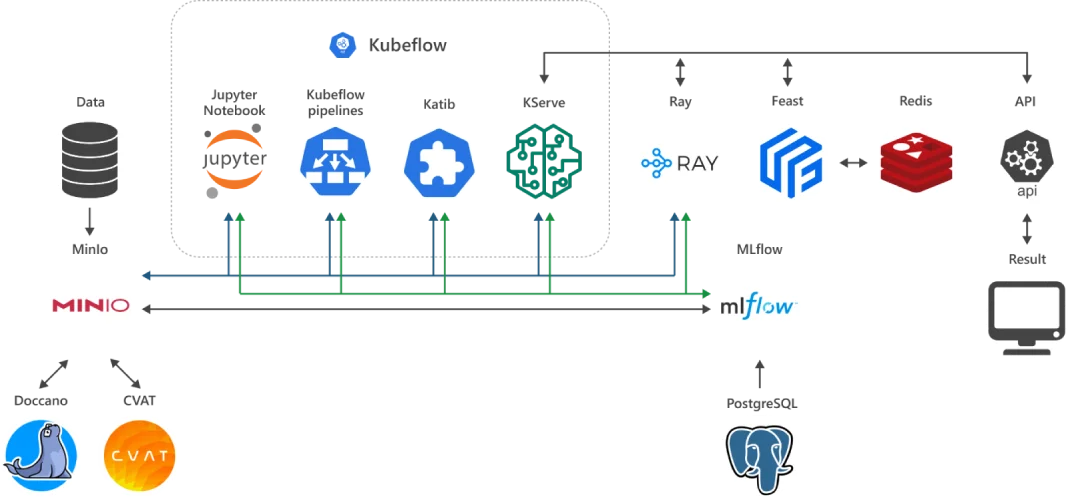
Из чего состоит ML Cloud?
Тест 14 дней бесплатно
Продукты для AI/ML


Позволяет быстро развернуть модель, подключить корпоративные данные, протестировать сценарии, запустить инференс и безопасно интегрировать Gen AI в бизнес-процессы

Облако с Kubernetes и NVIDIA GPU H200 NVL, H100, A100 NVL, L40S, L4 с тензорными ядрами для запуска рабочих нагрузок искусственного интеллекта и машинного обучения (AI/ML) в колективном облаке De Novo

Kubernetes для AI/ML, акселерированный NVIDIA GPU H200 NVL, H100, A100 NVL, L40S, L4 с тензорными ядрами на базе частного облака Hosted Private Infrastructure (HPI)
Как работают современные AI-решения от облачных провайдеров?
В современной ИТ-инфраструктуре AI-решения в облаке стали основой масштабируемых, продуктивных и гибких систем, способных решать сложные задачи обработки данных, автоматизации и аналитики. Основная идея — перенос вычислительной нагрузки и моделей искусственного интеллекта на облачные платформы, где ресурсы масштабируются динамически, а разработка и внедрение существенно упрощаются.
Типичная архитектура передовых AI-решений в облаке основывается на микросервисном подходе, контейнеризации (Docker, Kubernetes) и использовании специализированных вычислительных ресурсов — ускорителей GPU, TPU или FPGA, доступных через интерфейсы провайдеров. Такие технологические решения AI включают в себя сервисы для предварительной обработки данных (data pipelines), автоматизированного машинного обучения (AutoML), управления экспериментами, а также CI/CD для ML-моделей.
Облачные провайдеры AI-решений интегрируют новейшие фреймворки (TensorFlow, PyTorch, ONNX) и поддерживают serverless-парадигму в контексте inference-функций, что позволяет запускать модели по запросу без необходимости в выделенной инфраструктуре. Это особенно актуально для сценариев с высокой динамикой нагрузки — например, в e-commerce, финансовых аналитических системах или при real-time обработке изображений и видео.
Ключевое преимущество AI в облаке — это возможность масштабирования и снижение порога входа: вместо затрат на собственное GPU-оборудование компании могут использовать мощности провайдера и платить только за фактическое потребление ресурсов.
Это особенно выгодно для стартапов или R&D-отделов, которые активно экспериментируют с различными решениями искусственного интеллекта. Интеграция artificial intelligence в облаке также предусматривает глубокую поддержку практик DevOps и MLOps: автоматическое логирование результатов, контроль версий, непрерывное тестирование, а также интеграцию с корпоративными системами данных (Data Lake, DWH, API). Благодаря этому разработчики могут сосредоточиться на логике модели, не тратя время на настройку инфраструктуры.
Таким образом, AI-решения в облаке — это не просто сервис для запуска моделей, а полноценная экосистема, охватывающая все этапы жизненного цикла AI-продукта: от сбора данных до развёртывания и мониторинга в production-среде. Такие передовые AI-решения формируют основу новой волны цифровой трансформации, позволяя бизнесу быстрее принимать решения, эффективнее работать с данными и создавать инновационные сервисы на основе искусственного интеллекта.
Какие преимущества у облачного машинного обучения?
Облачное машинное обучение (MLaaS) стало ключевым компонентом современной data science-экосистемы, предоставляя разработчикам, аналитикам и инженерам гибкие, масштабируемые и экономически эффективные инструменты. Благодаря распределённой природе облачных сред, машинное обучение в облаке позволяет избежать капитальных затрат на физическую инфраструктуру и обеспечивает on-demand доступ к GPU, TPU и другим специализированным вычислительным ресурсам.
Одним из основных преимуществ является масштабируемость: облако для машинного обучения позволяет параллелить обучение, используя автоматическое масштабирование и распределённое обучение. Это критически важно для больших датасетов или архитектур deep learning. Также упрощается управление ресурсами через инфраструктуру как код (IaC) и контейнеризацию (например, запуск в кластерах Kubernetes или serverless-средах). Важной характеристикой ml cloud является интеграция с инструментами MLOps: контроль версий данных и моделей, CI/CD-пайплайны, автоматизированное тестирование и мониторинг в реальном времени. Это позволяет поддерживать высокое качество ПО на этапе inference, а также оперативно реагировать на data drift или изменение паттернов во входных данных.
Кроме того, машинное обучение в облаке значительно упрощает взаимодействие в командах: совместное использование артефактов, модульная структура пайплайнов, изолированные среды тестирования, валидации и production-деплоймента. Это особенно важно для сценариев с CI/CD и agile-разработкой в мультифункциональных командах. В целом, облачное машинное обучение обеспечивает эффективную среду для быстрого прототипирования, экспериментов, масштабирования и сопровождения программной разработки на всех этапах жизненного цикла — от raw-данных до стабильного продакшна с высокой доступностью.
Как облачные вычисления ускоряют развитие AI и ML?
Облачные вычисления AI играют ключевую роль в масштабировании, производительности и доступности искусственного интеллекта, особенно в условиях стремительного роста объёмов данных и сложности задач. Традиционная on-premise инфраструктура часто не способна обеспечить необходимую вычислительную мощность и гибкость, которые требуются для современных моделей deep learning, reinforcement learning или LLM. Вместо этого облачные вычисления искусственного интеллекта позволяют мгновенно получить доступ к высокопроизводительным кластерам GPU/TPU, масштабируемым хранилищам и управляемым сервисам автоматизации всего жизненного цикла ML/AI-проектов.
Благодаря распределённым вычислениям и встроенной поддержке контейнеризации (Kubernetes, Docker) artificial intelligence в облаке может обучаться в параллельном режиме с использованием стратегий вроде data parallelism, model parallelism или hybrid training, что существенно сокращает время обучения, например, LLM. Это критически важно для задач машинного зрения (computer vision), NLP или обработки временных рядов (time series), где обучение на локальной инфраструктуре может занимать дни или недели.
Помимо вычислительных преимуществ, облачные вычисления и искусственный интеллект тесно интегрируются на уровне автоматизации. Современные ML-стеки в облаке включают полную поддержку MLOps: автоматическое развёртывание моделей, контроль версий артефактов, мониторинг задержки ответа модели (inference latency), data drift и SLA, а также CI/CD пайплайны для обновлений без простоев. Это обеспечивает быстрый переход от прототипов к production-решениям.
С точки зрения архитектуры, machine learning в облаке использует инфраструктуру как код (IaC), serverless-технологии и event-driven подходы (например, запуск пайплайнов по триггерам из message-брокеров или объектных хранилищ). Это позволяет снизить операционные затраты и повысить надёжность системы, а также гибко масштабировать ресурсы в зависимости от потребностей каждого этапа пайплайна — от data ingestion до online inference.
Кроме того, облачные вычисления для machine learning упрощают управление данными: интеграция с Data Lake, feature store, data warehouse и stream-инфраструктурой позволяет централизованно хранить, обрабатывать и подавать данные в модели. Это обеспечивает консистентность, отслеживаемость (traceability) и соответствие политикам безопасности и доступа. В результате облачные вычисления AI не только снижают порог входа в разработку технологий, но и формируют среду, в которой AI/ML-проекты можно масштабировать от лабораторного прототипа до глобального продакшна с высоким уровнем нагрузки, SLA и fault tolerance.
Облачная платформа для AI — инфраструктура, которая масштабируется вместе с потребностями
Современная облачная AI-платформа — это ключевой элемент масштабируемой AI-экосистемы, позволяющий компаниям реализовывать полноценные пайплайны машинного обучения без необходимости строить сложную инфраструктуру с нуля. Такая платформа обеспечивает управление полным жизненным циклом разработки: от сбора и предварительной обработки данных до обучения, валидации, деплоймента, мониторинга и переобучения.
Основное преимущество, которое даёт облачная платформа для AI, — это автоматическое масштабирование вычислительных ресурсов в ответ на изменение нагрузки. Например, во время массового обучения моделей или выполнения ресурсоёмких задач (таких как гиперпараметрический поиск или distributed training) вычислительные ресурсы масштабируются горизонтально с использованием GPU/TPU кластеров. В периоды низкой активности инфраструктура автоматически сворачивается, снижая затраты.
AI-платформа на базе облака реализована на основе микросервисной и событийно-ориентированной архитектуры с глубокой интеграцией DevOps- и MLOps-практик. Инфраструктура описывается декларативно через IaC (Terraform, Pulumi), пайплайны автоматизируются через workflow-движки (Argo, Airflow), а деплоймент выполняется с использованием container registry, policy-based promotion и автоматического тестирования качества (validation hooks, integration tests).
Облачная платформа искусственного интеллекта также включает управляемые сервисы для хранения артефактов, истории обучений, логов, метрик, а также реализует полноценное наблюдение (observability) — с мониторингом latency, throughput, error rate и изменений распределения входящих данных (concept/data drift). Это позволяет оперативно выявлять деградацию производительности моделей в продакшн-среде.
Особенностью облачной AI-платформы является её готовность к гибридным и мульти-региональным сценариям. Платформы поддерживают как централизованное, так и edge-развёртывание моделей — с возможностью синхронизации конфигураций, автоматического обновления inference-агентов и агрегации телеметрии в основную платформу. Таким образом, облачная платформа для AI позволяет инженерным командам сосредоточиться на качестве моделей и скорости инноваций, не тратя время на обслуживание инфраструктуры. Её масштабируемость, модульность и автоматизация делают её ключевым инструментом для любого предприятия, стремящегося интегрировать AI в свои продукты или сервисы на уровне продакшна.
Что такое платформа для машинного обучения и как она работает?
Платформа для машинного обучения — это комплексная программно-аппаратная среда, предназначенная для автоматизации всех этапов построения, развёртывания и сопровождения машинного обучения. Такая платформа служит центральной точкой для дата-инженеров, дата-сайентистов, MLOps-инженеров и разработчиков, обеспечивая совместную работу с данными, кодом, экспериментами и production-решениями.
С технической точки зрения, платформа машинного обучения реализует полный жизненный цикл разработки — от подготовки данных до эксплуатации (инференса, inference) — в виде модульной архитектуры. К её основным компонентам относятся: • среда обработки и трансформации данных (ETL, feature engineering); • хранилище датасетов, артефактов и моделей (object storage, model registry); • инструменты экспериментов (ноутбуки, интерфейсы запуска обучения); • механизмы автоматического обучения, гиперпараметрического поиска и валидации; • пайплайны развёртывания моделей (CI/CD, canary/staged rollout); • модули мониторинга производительности (latency, accuracy, drift detection).
В центре системы — платформа ML, которая координирует выполнение этих процессов с помощью task scheduler’ов и систем оркестрации декларативного описания workflow (например, через YAML или DSL). Это позволяет автоматизировать запуск пайплайнов, контролировать зависимости между задачами и обеспечивать воспроизводимость экспериментов.
Платформа AI ML тесно интегрирована с DevOps- и MLOps-инструментами: от контроля версий моделей и метаданных (MLflow, DVC) до логирования и телеметрии в inference-среде. Благодаря этому разработчики могут не только создавать модели, но и поддерживать их качество на всём жизненном цикле. Ключевой особенностью является масштабируемость: платформа AI адаптируется под нужды задачи — будь то batch-обработка больших объёмов данных или inference в реальном времени на edge-устройствах. Для этого используются динамическое управление ресурсами, автоматический autoscaling, поддержка GPU/TPU и контейнеризированное выполнение.
Также важную роль играет безопасность и контроль доступа: платформа для искусственного интеллекта реализует многоуровневую аутентификацию, RBAC, audit-логи и политики управления данными — особенно важно для регулируемых отраслей, где критичны прозрачность и воспроизводимость ML-решений. В итоге, платформа для машинного обучения — это не просто инструмент для обучения, а стратегическая инфраструктура для создания, масштабирования и поддержки AI-систем. Она обеспечивает стандартизацию процессов, сокращает time-to-market и позволяет компаниям эффективно реализовывать ML-стратегии в любом масштабе — от R&D до массового продакшна.
Облачный AI/ML-сервис — оптимизированная платформа для MLOps
В современных архитектурах машинного обучения облачный сервис AI выступает как централизованная управляемая платформа, ориентированная на обеспечение полного жизненного цикла ML-моделей — от сбора и обработки данных до деплоймента, мониторинга и автоматического обновления. Такой сервис является основой для внедрения MLOps-практик, которые позволяют стандартизировать процесс разработки, развёртывания и поддержки моделей в продакшн-среде.
Основное преимущество, которое даёт ml сервис, заключается в возможности автоматизации сложных задач через пайплайны: трансформация данных, гиперпараметрический поиск, обучение в распределённом режиме, проверка качества и развёртывание на inference-инфраструктуре с автомасштабированием и мониторингом SLA. Большинство решений реализованы в виде микросервисной архитектуры с поддержкой REST/gRPC API, что упрощает интеграцию с другими компонентами системы.
Сервис машинного обучения также позволяет централизованно управлять метаданными, артефактами, версиями моделей и данных, обеспечивая воспроизводимость (reproducibility) и отслеживаемость (traceability) всех изменений. Через интеграцию с CI/CD-системами возможно реализовать контроль качества моделей на каждом этапе развёртывания — с автоматическим тестированием, откатом (rollback) и продвижением изменений по средам (environment promotion).
Облачный сервис машинного обучения обычно поддерживает различные типы вычислений — batch, stream, real-time inference — и динамически масштабируется благодаря использованию контейнеризации, бессерверных (serverless) или кластерных вычислений. Это позволяет сократить задержку для критичных задач (например, при обнаружении аномалий в системах кибербезопасности или рекомендательных системах) и снизить стоимость эксплуатации за счёт оптимизации ресурсов во время простоя.
Встроенные функции мониторинга и наблюдаемости (observability) позволяют контролировать не только технические показатели (latency, error rate), но и специфические ML-метрики — accuracy, precision, recall, drift, confidence distribution. В сочетании с автоматическими триггерами переобучения это позволяет поддерживать модели в актуальном состоянии даже при динамичных изменениях данных.
Современные облачные ML-сервисы также учитывают требования безопасности и контроля доступа: RBAC, audit-треки, шифрование артефактов и секретов, политики data governance. Это критически важно для корпоративных сценариев, где решения работают с персональными или коммерчески чувствительными данными.
В итоге, облачный сервис AI — это не просто вычислительная платформа, а полноценный технологический стек, ориентированный на реализацию непрерывного цикла машинного обучения. Его масштабируемость, автоматизация и интеграция с современными DevOps-подходами позволяют командам быстро запускать, тестировать, адаптировать и поддерживать AI-решения в production-ready среде.
ML as a Service — кому подходит и как выбрать провайдера?
ML as a Service (MLaaS) — это модель предоставления инструментов машинного обучения как облачной услуги, позволяющая компаниям создавать, обучать, развёртывать и масштабировать модели без необходимости управления сложной инфраструктурой. Такой подход особенно ценен для команд, которые хотят сосредоточиться на решении бизнес-задач, а не на построении и поддержке внутренних AI/ML-платформ.
Услуга AI ML подходит:
- стартапам и небольшим командам, у которых нет собственных специалистов DevOps или MLOps;
- предприятиям, которые стремятся быстро протестировать гипотезу или MVP без инвестиций в hardware;
- крупным компаниям — как часть гибридной стратегии, например, для non-critical моделей, обработки данных вне основного дата-центра или edge inference.
При выборе провайдера услуг AI ML следует учитывать несколько критических аспектов:
- Масштабируемость и тип вычислительных ресурсов: важно иметь доступ к GPU/TPU, autoscaling-кластерам, а также возможность выполнения как batch-, так и real-time inference.
- Поддержка MLOps: версионирование моделей и данных, CI/CD пайплайны, rollback, тестирование, environment promotion, а также observability (метрики, логирование, алерты).
- Гибкость API и SDK: наличие поддержки REST/gRPC, интеграция с популярными ML-фреймворками, поддержка кастомных контейнеров и runtime-сред.
- Безопасность и соответствие: RBAC, шифрование, audit logs, контроль доступа к конфиденциальным данным — особенно важно для регулируемых отраслей.
- Стоимость и модель биллинга: прозрачность ценообразования, оплата за использование (pay-as-you-go), возможность предварительного прогнозирования стоимости пайплайнов.
Современные сервисы AI и ML часто включают дополнительные компоненты: AutoML, Data Labeling, Feature Store, Model Registry — всё это сокращает время разработки и повышает продуктивность команд.
В целом, ML as a Service — это оптимальный вариант для организаций, которые хотят быстро масштабировать AI-инициативы, не жертвуя надёжностью и качеством. Главное — чётко понимать свои требования к технологиям, безопасности, производительности и обслуживанию, чтобы выбрать сервис, который не просто «работает», а полностью соответствует целям и архитектуре вашего AI-решения.
Управление ML-моделями — как контролировать жизненный цикл машинного обучения в облаке
В облачной среде управление ML-моделями выходит далеко за рамки этапа их обучения. Это комплексный процесс, охватывающий все фазы жизненного цикла — от создания прототипа до мониторинга производительности в продакшене и планового переобучения. Эффективное управление моделями ML обеспечивает контроль качества, стабильность работы и возможность масштабирования AI-систем.
На практике ML management включает:
- Версионирование (Versioning) моделей, датасетов, кода и конфигураций — для обеспечения полной воспроизводимости (reproducibility) и трассировки источников ошибок;
- Регистрацию и контроль артефактов, хранение метаданных и результатов экспериментов;
- Оркестрацию ML-пайплайнов с использованием DAG/DSL-описания этапов: обработка данных, обучение, валидация, деплоймент, тестирование;
- CI/CD для ML, включая автоматическое развёртывание моделей в staging и production средах;
- Мониторинг производительности: метрики inference latency, throughput, accuracy, precision, а также контроль drift-метрик (data и concept drift);
- Оповещения (Alerting) и триггеры переобучения, запускающие retraining в ответ на деградацию модели или изменение характеристик входных данных;
- Контроль доступа на основе ролей (RBAC), ведение журнала действий (Audit), автоматическое применение политик безопасности и управления (policy enforcement) — для управления доступом, логирования действий и соблюдения нормативных требований.
Типичное решение для управления ML-моделями (ML model management) в облаке реализуется через комбинацию контейнеризованных сред (Kubernetes), систем исполнения пайплайнов (pipeline engine, например, Airflow, Argo), модельного реестра, логгеров и трекинговых систем. Это позволяет централизованно управлять сотнями моделей, одновременно работающих в разных бизнес-доменах. В результате, управление ML в облаке — это не просто набор инструментов, а полноценная стратегия масштабирования AI-решений с гарантией контроля, стабильности и адаптивности в условиях изменяющейся нагрузки и динамики данных.
Как обеспечить оптимизацию, стабильность и масштабирование моделей в облаке для MLOps?
Для эффективной работы AI-систем в облачной среде критически важно внедрить надёжную архитектуру MLOps в облаке (MLOps Cloud). Это означает, что все этапы жизненного цикла модели — от обучения до развёртывания, мониторинга и переобучения — должны быть автоматизированы, управляемы и масштабируемы. Оптимизация достигается через использование контейнеризации, автоматического масштабирования (autoscaling) вычислительных ресурсов, в том числе GPU/TPU-кластеров, и эффективных систем оркестрации — таких, как pipeline engines.
Облако для MLOps позволяет динамически адаптировать инфраструктуру к изменениям нагрузки и гибко распределять вычисления между узлами, что повышает эффективность использования ресурсов. Стабильность обеспечивается через пайплайны непрерывной интеграции и развёртывания (CI/CD), автоматическую проверку работоспособности (health-check), контроль качества моделей (точность, задержка, смещение данных — data drift), механизмы быстрого отката к предыдущей версии (rollback) и систему оповещений (alerting).
Масштабирование реализуется как вертикально (увеличение мощности ресурсов), так и горизонтально — через параллельное развёртывание моделей в разных регионах, модульную архитектуру пайплайнов и поддержку одновременной работы нескольких моделей (multi-model serving).
В итоге, MLOps в облаке — это адаптивная инфраструктура, позволяющая быстро внедрять, масштабировать и контролировать модели машинного обучения на каждом этапе их жизненного цикла в production-среде.