






Что такое Machine Learning?
2024-05-17

В эпоху бума цифровых технологий, машинное обучение становится преобразующей силой, позволяющей использовать огромный потенциал данных. Алгоритмы МО обладают замечательной способностью учиться на данных, выявлять закономерности, делать прогнозы и автоматизировать принятие решений.
Машинное обучение (Machine Learning, ML) — это класс методов искусственного интеллекта (ИИ), объединяющий подходы и технологии для создания алгоритмов, способных самостоятельно обучаться на основе данных. В отличие от традиционных методов, при которых вычислительные системы запрограммированы на выполнение определенных задач, ML-модели способны улучшать свою работу с течением времени, анализируя данные и выявляя в них закономерности. Это позволяет ML-системам решать задачи, которые сложно или невозможно запрограммировать вручную.
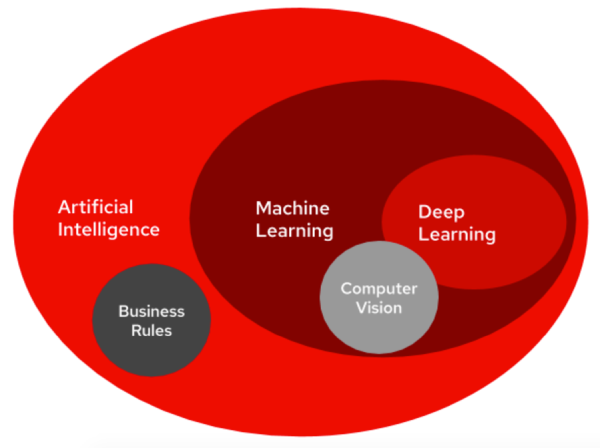
Методы машинного обучения
Существует множество различных типов ML-алгоритмов, каждый из которых подходит для решения определенных задач. К числу наиболее распространенных типов Machine Learning можно отнести:
- Обучение с учителем (Supervised learning). Алгоритм обучается на наборе данных, в котором каждый пример имеет метку, указывающую на его класс.
- Обучение без учителя (Unsupervised learning). Алгоритм обучается на наборе данных, который не имеет меток.
- Полууправляемое обучение (Semi-supervised learning). Алгоритм обучается на наборе данных, который содержит как помеченные, так и непомеченные примеры.
- Обучение с подкреплением (Reinforcement Learning, RL). Алгоритм учится выполнять задачу, получая «вознаграждение» или «штраф» за свои действия.
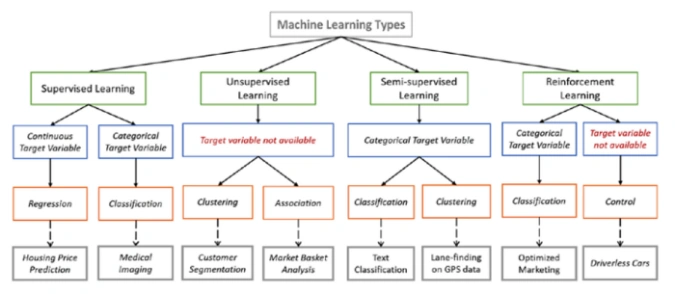
Ниже мы рассмотрим эти методы более детально.
Отметим также, что сегодня ML активно используется во многих сферах экономики, Вот лишь некоторые из них.
- Здравоохранение. Для диагностики заболеваний, разработки лекарств, анализа медицинских изображений.
- Финансы. Для обнаружения мошенничества, оценки рисков, управления активами.
- Маркетинг. Для персонализации рекламы, таргетирования клиентов, анализа данных о клиентах и заказчиках.
- Производство. Для прогнозирования спроса, оптимизации производственных процессов, контроля качества.
- Робототехника. Для разработки самоуправляемого транспорта, управления различными типами роботов.
Сегодня технологии Machine Learning развиваются очень быстро, их потенциал для решения различных задач огромен и в дальнейшем можно ожидать, ML будет оказывать возрастающее влияние на многие сферы нашей жизни. Но, прежде, чем перейти к более детальному рассмотрению подходов и методов ML, сделаем небольшой экскурс в историю.
Краткая история появления ML
Идея машинного обучения зародилась примерно в середине прошлого века.
Одним из пионеров этой области был знаменитый английский ученый Алан Тьюринг, который в работе «Вычислительные машины и разум» (Computing Machinery and Intelligence) (1950) описал возможность создания машин, способных «учиться».
В 60-х годах были разработаны первые алгоритмы машинного обучения, основанные на статистических методах.
В 70-х наступила эпоха символического искусственного интеллекта, когда компьютеры «учились» на правилах и логике.
В 80-х годах возник интерес к нейронным сетям, в основе работы которых лежат основные принципы функционирования головного мозга человека.
В 90-х годах произошел прорыв в области машинного обучения благодаря развитию алгоритмов, способных обрабатывать огромные объемы данных, а также тому, что, наконец, появились относительно доступные вычислительные мощности, которые позволили работать с моделями ML многим научным группам и компаниям по всему миру.
В 2000-х годах машинное обучение стало одной из самых быстро развивающихся областей ИИ благодаря растущей вычислительной мощности и развитию алгоритмов глубокого обучения, таких как сверточные нейронные сети (CNN) и рекуррентные нейронные сети (RNN).
2010-е годы можно назвать периодом расцвета глубокого обучения и его применения в различных областях, таких как компьютерное зрение, обработка естественного языка (NLP) и робототехника.
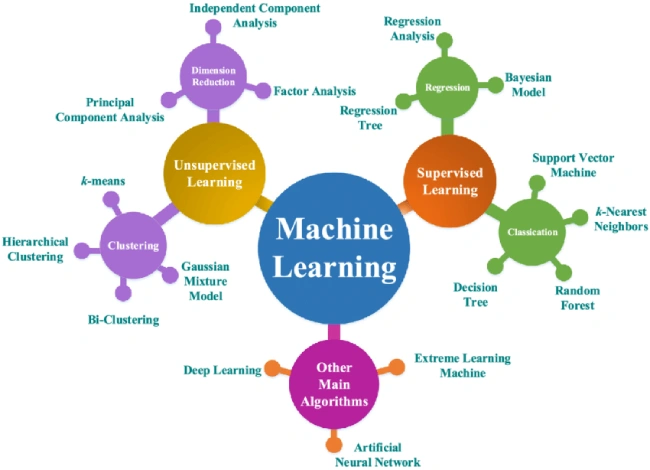
В частности в 2013-2015 годах отмечен резкий всплеск интереса к ML со стороны бизнеса и научного сообщества. Появляется большое количество новых приложений ML в различных областях, таких как финансы, здравоохранение и производство. Также появляются популярные платформы ML, такие как TensorFlow и PyTorch, делающие разработку и развертывание ML-моделей более доступными.
В период с 2015 по 2018 годы ML становится ключевым компонентом ИИ, стимулируя дальнейшие исследования и разработки. Происходят прорывы в области NLP: алгоритмы ML, основанные на нейронных сетях, достигают значительных успехов в задачах обработки естественного языка, таких как машинный перевод и чат-боты.
C 2020-2021 и по нынешний 2026 год активно развиваются технологии совместного обучения, позволяющие нескольким ML-моделям обучаться друг у друга, повышая общую производительность. Благодаря новой мощной аппаратной базе, существенный импульс получили нейроморфные вычисления (чьи принципы работы основаны на моделировании процессов человеческого мозга), развивается квантовое машинное обучение, в рамках которого исследуется потенциал квантовых вычислений для ускорения алгоритмов Machine Learning.
Также в последние годы активно развивается направление ML из облака — Machine Learning Cloud, когда учение модели происходит с использованием ресурсов мощного облака коммерческого оператора.
Теперь, после краткого исторического обзора, перейдем непосредственно к рассмотрению наиболее актуальных методов машинного обучения, используемых сегодня.
Управляемое обучение
Оно же — обучение с учителем (Supervised learning) — это самый распространенный тип машинного обучения. В данном случае алгоритм обучается на наборе данных, где каждый пример имеет метку. Метка описывает желаемый результат для данного примера. На основе этих данных алгоритм учится связывать входные данные с выходными метками.
Существует множество алгоритмов управляемого обучения, в их числе:
- Линейная регрессия. Используется для прогнозирования числового значения на основе одного или нескольких входных данных.
- Логистическая регрессия. Используется для классификации данных на категории.
- Деревья решений. Используются для принятия решений на основе набора правил.
- Метод k -ближайших соседей (KNN). Используется для классификации данных на основе похожести с другими данными в наборе.
- Поддержка векторных машин (SVM). Используется для классификации данных и регрессии.
Неуправляемое обучение
Или обучение без учителя (Unsupervised learning). Это тип машинного обучения, в котором алгоритм обучается на наборе данных без меток. Цель алгоритма — самостоятельно найти закономерности и выявить структуры в данных, сгруппировать объекты по схожим признакам и, возможно, сделать прогнозы о том, что к будет развиваться ситуация дальше.
Обучение без учителя часто используется для разделения данных на группы с похожими характеристиками (кластеризации), уменьшения количества признаков в данных без потери информации (снижения размерности), выявления необычных или отклоняющихся от нормы данных (обнаружение аномалий).
К числу алгоритмов обучения без учителя можно отнести:
- Метод k -средних — это алгоритм кластеризации, который разделяет данные на заранее определенное количество групп.
- Алгоритм приближенных k-средних. Более эффективный вариант предыдущего алгоритма, который может обрабатывать большие наборы данных.
- Анализ главных компонент. Метод снижения размерности, который выбирает наиболее информативные признаки в наборах данных.
Также возможна комбинация двух вышерассмотренных методов (с учителем и без учителя). Такую комбинацию, условно, можно назвать «полууправляемое обучение» (Semi-supervised learning), либо, смешанное обучение.
В этом случае, алгоритм обучается на наборе данных, который содержит как помеченные, так и непомеченные примеры. Помеченные примеры используются для обучения алгоритма, как в обучении с учителем, а непомеченные примеры применяются для поиска закономерностей в данных, как в случае обучения без учителя.
«Полууправляемое обучение» может оказаться эффективным в тех ситуациях, когда имеется небольшой набор помеченных и большой набор непомеченных данных. Например, при самообучении или совместном обучении ML-моделей.
Обучение с подкреплением
Обучение с подкреплением (Reinforcement Learning, RL) – это тип машинного обучения, в котором алгоритм учится на основе взаимодействия с окружающей средой.
В отличие от других методов ML, где алгоритм обучается на наборе данных с метками, в RL алгоритм получает «подкрепление» — «вознаграждение» или «штраф» — за те или иные результаты и со временем учится выбирать действия, которые максимизируют награду.
Преимущества RL:
- Способность к самообучению. Такие модели не требуют наличия большого набора данных с метками.
- Эффективность в сложных задачах. Модель RL может быть использована для задач, которые сложно или невозможно решить с помощью других методов машинного обучения.
- Адаптивность. RL-алгоритмы могут адаптироваться к новым условиям и задачам.
Глубокое обучение
Глубокое обучение (Deep Learning) — это подмножество алгоритмов и методов машинного обучения, которое использует для решения задач искусственные нейронные сети.
Искусственные нейронные сети (ИНС) — это математические модели, построенные по принципу работы биологических нейронных сетей (например, головного мозга человека).
ИНС состоят из многослойных сетей искусственных нейронов — специальных узлов (процессоров), каждый из которых выполняет некоторые простые вычисления. Каждый нейрон получает сигналы от других нейронов, обрабатывает их и формирует результирующий выходной сигнал. Информация проходит через слои сетей искусственных нейронов, подвергаясь трансформации и анализу на каждом этапе. Благодаря многослойной архитектуре Deep Learning позволяет выявлять сложные закономерности из огромных наборов данных и решать задачи ИИ, которые раньше казались невыполнимыми.
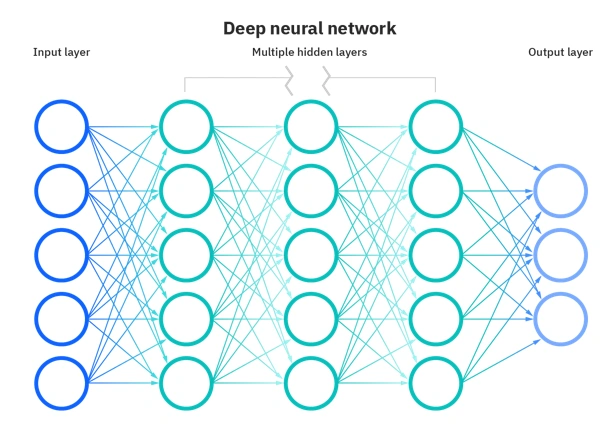
Существует несколько основных типов глубокого обучения:
- Сверточные нейронные сети (CNN). Такие сети анализируют входные данные (изображения, видео) по частям, используя небольшие "фильтры". Каждый фильтр сфокусирован на определенных признаках, таких как форма, цвета или текстуры. Пропуская данные через фильтры, CNN формируют иерархию признаков, которые позволяют распознавать и категорировать объекты изображения, а также определять закономерности в визуальных данных. Сверточные нейронные эффективны для распознавания образов, обработки изображений и видео.
- Рекуррентные нейронные сети (RNN) обрабатывают последовательные данные (текст, речь) с учетом контекста. Информация из предыдущих элементов последовательности влияет на то, как RNN интерпретирует текущий элемент (это, в целом, похоже на модель диалога между людьми). RNN будут идеальным решением для задач, где важен порядок и контекст. Они хорошо подходят для обработки естественного языка, понимание речи, машинного перевода.
- Трансформер — это более новая архитектура нейронных сетей (появилась в 2017 году), которая вывела обработку естественного языка на совершенно новый уровень эффективности. В отличие от нейросетей RNN, которые обрабатывают данные последовательно, модели-трансформеры могут одновременно «видеть» все элементы последовательности, учитывая взаимосвязи между ними. Это делает трансформеры эффективными и быстрыми при решении задач, связанных с длинными текстами.
Deep Learning позволяет легко решать задачи, которые раньше были невыполнимы (или трудновыполнимы) для вычислительных систем. К примру, это распознавание изображений и речи, «понимание» человеческого языка и генерирование адекватных ответов на вопросы, заданные человеком.
Какие задачи бизнеса могут решать машинное обучение и искусственный интеллект?
Машинное обучение (ML) и искусственный интеллект (ИИ, AI) – это мощные инструменты, которые могут помочь бизнесу во многих аспектах. К примеру ML/AI и позволяют автоматизировать многие рутинные задачи, повышают эффективность бизнес-процессов, улучшают обслуживание клиентов, способствуют разработке новых продуктов и услуг, могут выдавать ценные рекомендации на основе анализа огромных массивов данных.
Вот несколько примеров того, как Machine Learning и искусственный интеллект могут быть использованы для решения задач бизнеса.
- Автоматизация повторяющиеся задач, таких как ввод данных, обработка документов и обслуживание клиентов. Это позволяет высвободить время сотрудников для более сложной работы.
- Оптимизация бизнес-процессов. ML/AI может анализировать данные для выявления неэффективности и оптимизации бизнес-процессов, повышая производительность компании.
- Персонализация обслуживания. ML/AI помога.т анализировать данные о клиентах, чтобы предоставлять им персонализированные предложения, рекомендации и поддержку.
- Автоматизация ответов на вопросы и предсказание потребностей клиентов
- Обнаружение мошеннических транзакций и кибербезопасность
- Управление рисками.
Примеры применения Machine Learning на практике
Машинное обучение сегодня активно используется в различных сферах нашей жизни, от медицины и финансов до маркетинга и производства. Рассмотрим несколько примеров применения ML, которые помогут вам лучше понять, как эта технология может быть использована для решения реальных задач.
- Amazon, Netflix, Spotify. Используют ML для рекомендаций своих сервисов клиентам на основе персональной истории покупок, просмотров, предпочтений и других данных.
- Google, Facebook, Х (ранее Twitter). Используют ML для показа пользователям наиболее релевантной рекламы на основе их интересов, истории поиска, демографических данных, поведения в социальных сетях.
- Виртуальные помощники Apple Siri, Amazon Alexa, Google Assistant. Используют ML для понимания естественного языка и выполнения запросов пользователей.
- IBM Watson. Использует ML для анализа медицинских изображений, таких как рентгеновские снимки и МРТ, для помощи врачам в диагностике заболеваний.
- Verily. Использует ML для разработки алгоритмов, которые могут диагностировать заболевания на основе данных о пациентах, таких как их симптомы, медицинская история и результаты анализов.
- Walmart. Использует ML для прогнозирования спроса на товары, что помогает компании оптимизировать свои запасы и производство.
- Uber. Использует ML для прогнозирования спроса на поездки, что помогает компании оптимизировать распределение своих водителей.
Это лишь несколько примеров того, как шинное обучение используется в бизнесе.
По мере развития технологий, алгоритмы ML становятся всё более мощными и продуктивными, что позволят решать еще более сложные задачи. Компании, которые смогут эффективно использовать машинное обучение, лучат ощутимое конкурентное преимущество на рынке. Вместе с тем, стоит помнить, что Machine Learning — это не волшебная палочка. Для того чтобы технологии были эффективными, необходимо иметь качественные данные, квалифицированных специалистов и продуманную стратегию внедрения. Сочетание этих факторов существенно повышает вероятность эффективного использования ML-технологий.