






Новая технология от DeepMind может вызвать интенсивный рост производительности AI-кластеров
2025-04-21

Компания DeepMind, которая является частью Google, предложила новый подход к организации AI/ML-вычислений, который потенциально способен поднять эффективность ИИ без необходимости резкого наращивания вычислительных ресурсов.
Сфера искусственного интеллекта и машинного обучения на данный момент является, очевидно, основным генератором новостей в сфере ИТ. И если посмотреть на отраслевую ситуацию в общих чертах, то складывается впечатление, что все крупнейшие игроки идут сейчас по пути экстенсивного роста — наращивают вычислительные ресурсы и строят гигантские дата-центры для их размещения. Вопрос оптимизации и эффективности, при наличии современных акселераторов GPU/TPU, пока, вроде бы отходит на второй план. Но, это не совсем так, работа над повышением эффективности технологий ведется лучшими умами, просто результаты не всегда такие наглядные и показательные, как в случае, скажем, создания гигаваттного кампуса ЦОД.
Бывают, конечно, исключения. Как например, недавняя премьера LLM модели DeepSeek R1 от одноименной китайской компании, которая взбудоражила рынок в начале нынешнего года. Напомним, что эта модель показала очень хорошие результаты — на уровне OpenAI — располагая, предположительно, весьма скромными вычислительными ресурсами. Хотя, многие эксперты полагают, что большая часть ускорителей попросту была скрыта и никакого чуда здесь нет, все же стоит признать, что LLM R1 оказалась довольно эффективной, способной на равных тягаться с лучшими мировыми образцами. Такая ситуация подстегнула западные компании к поиску и разработке решений, которые, помимо экстенсивного, обеспечили еще и интенсивный рост, иными словами, позволили бы более эффективно использовать уже имеющиеся ресурсы, вместо простого наращивания вычислительных мощностей.

Один из очень перспективных вариантов предложила недавно компания DeepMind. Ныне это дочерняя структура Google, но с момента своего создания в 2010 году компания специализировалась на технологиях машинного (Maschine Learning, ML) и глубокого обучения (Deep Learning, DL). В январе нынешнего года DeepMind представила результаты собственного исследования, которое показывает высокую эффективность новой методики обучения ИИ-моделей, которая получила название Streaming DiLoCo with overlapping communication (потоковое обучение DiLoCo с перекрывающейся коммуникацией). В основе нового метода лежит более идея DiLoCo (Distributed Low-Communication Training). DiLoCo это метод распределённого обучения больших языковых моделей (LLM), разработанный для эффективной работы на кластерах с ограниченной пропускной способностью сетевых каналов.
Традиционные подходы требуют тесно связанных ускорителей с высокой пропускной способностью и низкой задержкой для обмена градиентами и другими промежуточными данными на каждом шаге оптимизации. В отличие от этого подхода, DiLoCo позволяет обучать модели на «островках» устройств с ограниченной связностью, значительно снижая объем необходимого сетевого трафика без ущерба качеству обучения моделей. К примеру, исследования показали, что DiLoCo на 8 узлах достигает результатов, сопоставимых с полностью синхронной оптимизацией, при этом сокращая объём передаваемых данных в 500 раз.
Технология Streaming DiLoCo, разработанная DeepMind, представляет собой усовершенствованную версию метода, позволяющую синхронизировать подмножества параметров по расписанию и сокращать объем передаваемых данных без потери производительности. По данным компании этот подход требует в 400 раз меньшей пропускной способности сети, что делает его перспективным для обучения моделей на распределённых кластерах с ограниченной связностью.
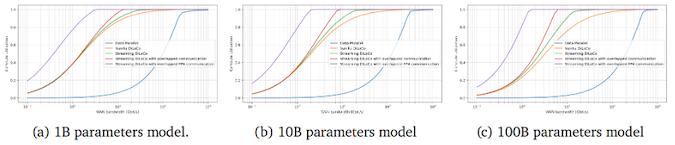
Сокращение сетевой нагрузки критически важно для обучения моделей и будущего развития ИИ, поскольку затраты на эффективный интерконнект стремительно растут и любой подход, который позволит их сократить (без потери общей эффективности обучения) потенциально способна вызвать технологический, а за ним и рыночный, прорыв в сфере AI/ML. Еще одним преимуществом Streaming DiLoCo является то, что технология потенциально позволяет эффективно объединить ИИ-кластеры и дата-центры, работающие на большом удалении это, в свою очередь открывает возможность создания огромных по суммарной мощности «гиперкластеров» без необходимости создания огромных локальных площадок (что повсеместно происходит сегодня). Соответственно, в процесс могут включаться более мелкие операторы и дата-центры.
На данный момент Streaming DiLo, по словам DeepMind, все еще находится на стадии доработки и тестирования, но очевидно, что она в том или ином виде, вскоре выйдет на рынок, а это в свою очередь может очень ощутимо подстегнуть развитие ИИ-отрасли в глобальном масштабе.