






Нова технологія від DeepMind може стимулювати інтенсивне зростання продуктивності AI-кластерів
2025-04-21

Компанія DeepMind, яка є частиною Google, запропонувала новий підхід до організації AI/ML-обчислень, що потенційно здатний підняти ефективність ШІ без необхідності різкого нарощування обчислювальних ресурсів.
Галузь штучного інтелекту та машинного навчання на цей час є, очевидно, основним драйвером новин у сфері ІТ. Якщо подивитися на ситуацію загалом, то складається враження, що всі найбільші гравці йдуть зараз шляхом екстенсивного зростання — нарощують обчислювальні ресурси та будують гігантські дата-центри для їх розміщення. Питання оптимізації та ефективності, за наявності сучасних акселераторів GPU/TPU, поки що, начебто, відходить на другий план. Але, це не зовсім так, робота над підвищенням ефективності технологій ведеться найкращими спеціалістами, просто результати не завжди такі наочні та показові, як у разі, скажімо, створення гігаватного кампусу ЦОД.
Бувають, звісно, винятки. Як, наприклад, нещодавня прем'єра LLM моделі DeepSeek R1 від однойменної китайської компанії, яка розбурхала ринок на початку нинішнього року. Нагадаємо, що ця модель показала дуже хороші результати — на рівні OpenAI - маючи, імовірно, дуже скромні обчислювальні ресурси. Хоча, багато експертів вважають, що більшість прискорювачів просто була прихована й ні якого дива тут немає, все ж варто визнати, що LLM R1 виявилася досить ефективною, здатною на рівних тягатися з кращими світовими зразками. Така ситуація спонукала західні компанії до пошуку та розробки рішень, які, крім екстенсивного, забезпечили ще й інтенсивне зростання, інакше кажучи, дозволили б більш ефективно використовувати наявні ресурси замість простого нарощування обчислювальних потужностей.

Один із дуже перспективних варіантів запропонувала нещодавно компанія DeepMind. Нині це дочірня структура Google, але з моменту свого створення у 2010 році компанія спеціалізувалася на технологіях машинного (Maschine Learning, ML) та глибокого навчання (Deep Learning, DL). У січні нинішнього року DeepMind представила результати власного дослідження, яке показує високу ефективність нової методики навчання ШІ-моделей, яка отримала назву Streaming DiLoCo with overlapping communication (потокове навчання DiLoCo з комунікацією, що перекривається).
В основі нового методу лежить ідея DiLoCo (Distributed Low-Communication Training). DiLoCo це метод розподіленого навчання великих мовних моделей (LLM), розроблений для ефективної роботи на кластерах з обмеженою пропускною здатністю мережевих каналів. Традиційні підходи вимагають тісно пов'язаних прискорювачів з високою пропускною здатністю та низькою затримкою для обміну градієнтами та іншими проміжними даними на кожному етапі оптимізації. На відміну від цього підходу, DiLoCo дозволяє навчати моделі на «островах» пристроїв з обмеженою зв'язністю, значно знижуючи обсяг необхідного мережевого трафіку без шкоди для якості навчання моделей. Наприклад, дослідження показали, що DiLoCo на 8 вузлах досягає результатів, порівнянних з повністю синхронною оптимізацією, при цьому скорочуючи обсяг даних, що передаються в 500 разів.
Технологія Streaming DiLoCo, розроблена DeepMind, є удосконаленою версією методу, що дозволяє синхронізувати підмножини параметрів за розкладом і скорочувати обсяг переданих даних без втрати продуктивності. За даними компанії, цей підхід вимагає в 400 разів меншої пропускної спроможності мережі, що робить його перспективним для навчання моделей на розподілених кластерах з обмеженою зв'язністю.
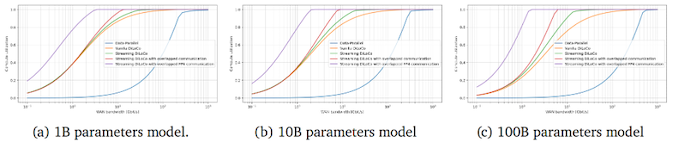
Скорочення мережного навантаження є критично важливим для навчання моделей та майбутнього розвитку ШІ, оскільки витрати на ефективний інтерконнект стрімко зростають і будь-який підхід, який дозволить їх скоротити (без втрати загальної ефективності навчання) потенційно здатна викликати технологічний, а за ним і ринковий прорив у сфері AI/ML. Ще однією перевагою Streaming DiLoCo є те, що технологія потенційно дозволяє ефективно об'єднати ШІ-кластери та дата-центри, що працюють на великому видаленні, це, своєю чергою, відкриває можливість створення величезних за сумарною потужністю «гіперкластерів» без необхідності створення величезних локальних майданчиків (що повсюдно відбувається сьогодні). Відповідно, у процес можуть включатися дрібніші оператори та дата-центри.
На цей час Streaming DiLo, за словами DeepMind, все ще перебуває на стадії доопрацювання та тестування, але очевидно, що вона в тому чи іншому вигляді незабаром вийде на ринок, а це, своєю чергою, може дуже відчутно підштовхнути розвиток ШІ-галузі в глобальному масштабі.