





An AI/ML platform for deploying, training, and running AI/ML models
A ready-to-use machine learning environment — no need to waste time setting up infrastructure — deployed in the cloud with NVIDIA GPUs.
ML Cloud combines an integrated, pre-configured and self-contained collection of "best of breed" open source MLOps tools with the NVIDIA H200 NVL / H100 / A100 NVL / L40s / L4 accelerators.
The ready-to-use ML engineer workspace is a significant lowering of the entry barrier to the world of AI/ML. And the latest NVIDIA tensor accelerators provide unattainable performance for other technologies on the tasks of machine learning and productive inference.
Just log in and start training, deploying, or running inference on your models — without any hassle.

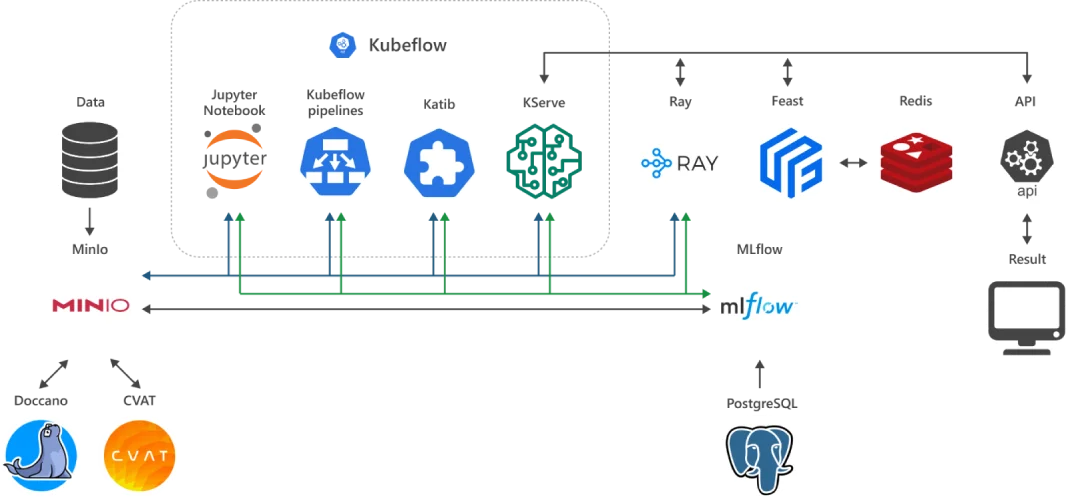
What does ML Cloud include?
14 days Free Trial
Products for AI/ML


It allows you to quickly deploy a model, connect corporate data, test scenarios, run inference, and securely integrate Gen AI into business processes

Cloud with Kubernetes and NVIDIA GPU H200 NVL, H100, A100 NVL, L40S, L4 with tensor cores to run artificial intelligence and machine learning (AI/ML) workloads

AI/ML-accelerated Kubernetes with NVIDIA GPU H200 NVL, H100, A100 NVL, L40S, L4 with Tensor Cores on Hosted Private Infrastructure (HPI)
How do modern AI solutions provided by cloud services work?
In today's IT infrastructure, AI solutions in the cloud have become the foundation for scalable, productive, and flexible systems capable of solving complex tasks in data processing, automation, and analytics. The main idea is to transfer the computational load and artificial intelligence models to cloud platforms, where resources are dynamically scaled and development and implementation are significantly simplified.
The typical architecture of advanced AI solutions in the cloud is based on a microservices approach, containerization (Docker, Kubernetes), and the use of specialized computing resources—GPU, TPU, or FPGA accelerators—available through provider interfaces. Such AI technology solutions include services for data preprocessing (data pipelines), automated machine learning (AutoML), experiment management, and CI/CD for ML models.
Cloud AI solution providers integrate the latest frameworks (TensorFlow, PyTorch, ONNX) and support a serverless paradigm for inference functions, enabling models to run on demand without needing dedicated infrastructure. This is particularly relevant for scenarios with high load dynamics—for instance, in e-commerce, financial analytics systems, or real-time image and video processing.
The key advantage of AI in the cloud is the ability to scale and lower the barrier to entry. Instead of spending on their own GPU equipment, companies can utilise the provider's capacity and pay only for the actual resources they use. This is especially beneficial for startups and R&D departments that are actively experimenting with various AI solutions. The integration of artificial intelligence in the cloud also provides robust support for DevOps and MLOps practices, including automatic logging of results, version control, continuous testing, and integration with corporate data systems such as Data Lake, DWH, and API. As a result, developers can focus on the logic of the model without spending time on infrastructure setup.
So, AI solutions in the cloud are not just a service for running models but a complete ecosystem that encompasses all stages of the AI product lifecycle: from data collection to deployment and monitoring in a production environment. Such advanced AI solutions serve as the foundation for a new wave of digital transformation, enabling businesses to make faster decisions, manage data more efficiently, and develop innovative services based on artificial intelligence.
What are the benefits of cloud-based machine learning?
Cloud-based machine learning as a service (MLaaS) has become a key component of today’s data science ecosystem, providing developers, analysts, and engineers with flexible, scalable, and cost-effective tools. Thanks to the distributed nature of cloud environments, cloud-based machine learning eliminates capital expenditures on physical infrastructure and offers on-demand access to GPUs, TPUs, and other specialized computing resources.
One of the main advantages is scalability: the machine learning cloud allows you to parallelize training using automatic scaling and distributed learning. This is critical for large datasets or deep learning architectures. It also simplifies resource management through infrastructure as code (IaC) and containerization (for example, running in Kubernetes clusters or serverless environments). An important feature of the ml cloud is integration with MLOps tools: data and model version control, CI/CD pipelines, automated testing, and real-time monitoring. This allows you to maintain high software quality at the inference stage, as well as quickly respond to data drift or changing patterns in the input data.
Furthermore, cloud machine learning significantly facilitates team collaboration by providing shared artifacts, a modular pipeline structure, and distinct environments for testing, validation, and production deployment. This aspect is particularly crucial for CI/CD and agile development scenarios within cross-functional teams. Overall, cloud machine learning offers an efficient environment for rapid prototyping, experimentation, scaling, and support for software development throughout all stages of the lifecycle — from raw data to stable production with high availability.
How does cloud computing AI accelerate the development of AI and ML?
AI cloud computing plays a crucial role in the scalability, performance, and accessibility of AI, especially given the rapid growth in data volumes and solution complexity. Traditional on-premise infrastructure often lacks the necessary computing power and flexibility required for modern deep learning, reinforcement learning, or LLM models. In contrast, AI cloud computing provides instant access to high-performance GPU/TPU clusters, scalable storage, and managed services to automate the entire ML/AI project lifecycle.
Thanks to distributed computing and built-in support for containerization (Kubernetes, Docker), AI in the cloud can be trained in parallel using strategies such as data parallelism, model parallelism, or hybrid training, which significantly reduces training time for large language models (LLMS). This is critical for tasks such as computer vision, NLP, or time series processing, where training on local infrastructure can take days or weeks.
Along with computational advantages, cloud computing and AI are closely integrated at the automation level. Modern ML stacks in the cloud feature comprehensive MLOps support: automatic model deployment, artifact version control, monitoring of model response latency (inference latency), data drift management, and SLAs, along with CI/CD pipelines for uninterrupted updates. This facilitates a swift transition from prototypes to production solutions.
From an architectural perspective, machine learning in the cloud employs infrastructure as code (IaC), serverless technologies, and event-driven approaches (e.g., triggering pipelines based on events from message brokers or object stores). This reduces operational costs and increases system reliability, while also allowing for flexible scaling of resources based on the needs of each stage of the pipeline—from data ingestion to online inference.
In addition, cloud computing for machine learning simplifies data management: integration with Data Lake, feature store, data warehouse, and stream infrastructure allows you to centrally store, process, and feed data to models. This ensures consistency, traceability, and compliance with security and access policies. As a result, cloud computing for AI not only reduces the barrier to entry in technology development but also creates an environment in which AI/ML projects can be scaled from laboratory prototype to global production with high load, SLA, and fault tolerance.
Cloud platform for AI: infrastructure that scales with your needs
A modern cloud AI platform is a crucial component of a scalable AI ecosystem, allowing companies to implement comprehensive machine learning pipelines without needing to construct complex infrastructure from the ground up. This platform oversees the entire development lifecycle: from data collection and preprocessing to training, validation, deployment, monitoring, and retraining.
The main advantage of a cloud platform for AI is the automated scaling of computing resources in response to changing workloads. For example, when training models in large numbers or performing resource-intensive tasks (such as hyperparameter tuning or distributed training), computing resources are scaled horizontally using GPU/TPU clusters. During periods of low activity, the infrastructure is automatically scaled down to reduce costs.
The cloud-based AI platform is built on a microservice and event-driven architecture, featuring deep integration of DevOps and MLOps practices. The infrastructure is defined declaratively through Infrastructure as Code (Iac) tools such as Terraform and Pulumi. Automated pipelines operate with workflow engines like Argo and Airflow, while deployment is managed through a container registry, policy-based promotion, and automatic quality testing, including validation hooks and integration tests.
Additionally, the cloud-based AI platform offers managed services for storing artifacts, training history, logs, and metrics, while also ensuring full observability. This includes monitoring latency, throughput, error rates, and changes in the distribution of input data, such as concept and data drift. This setup enables quick detection of model performance degradation within the production environment.
A feature of the cloud AI platform is its readiness for hybrid and multi-regional scenarios. The platforms support both centralized and edge deployment of models — with the ability to synchronize configurations, automatically update inference agents, and aggregate telemetry into the core platform. Thus, the cloud AI platform allows engineering teams to focus on model quality and innovation speed, without wasting time on infrastructure maintenance. Its scalability, modularity, and automation make it a key tool for any enterprise seeking to integrate AI into its products or services at the production level.
What is a machine learning platform and how does it work?
A machine learning platform is a comprehensive hardware and software environment designed to automate all stages of building, deploying, and maintaining machine learning. It serves as a central hub for data engineers, data scientists, MLOps engineers, and developers to collaborate on data, code, experiments, and production solutions.
From a technical standpoint, a machine learning platform implements the complete development lifecycle—from data preparation to operation (inference)—in a modular architecture. Its main components include:
• a data processing and transformation environment (ETL, feature engineering);
• a repository of datasets, artifacts, and models (object storage, model registry);
• experimentation tools (notebooks, interfaces for launching training);
• mechanisms for automatic training, hyperparameter search, and validation;
• model deployment pipelines (CI/CD, canary/staged rollout);
• performance monitoring modules (latency, accuracy, drift detection).
At the core of the system is the ML platform, which coordinates the execution of these processes using task schedulers and declarative workflow orchestration systems (for example, via YAML or DSL). This allows for the automation of pipeline launches, control of dependencies between tasks, and ensures the reproducibility of experiments.
The AI ML platform integrates tightly with DevOps and MLOps tools, ranging from model and metadata version control (MLflow, DVC) to logging and telemetry in the inference environment. As a result, developers can not only create models but also maintain their quality throughout the entire lifecycle. A key feature is scalability: the AI platform adapts to the needs of the task, whether it involves batch processing of large amounts of data or real-time inference on edge devices. To achieve this, it utilises dynamic management of computing resources, automatic autoscaling, GPU/TPU support, and containerized execution.
Security and access control also play an important role: the AI platform implements multi-level authentication, RBAC, audit logs, and data management policies—especially important for regulated industries where transparency and reproducibility of ML solutions are critical. In short, a machine learning platform is not just a training tool but a strategic infrastructure for building, scaling, and supporting AI systems. It standardizes processes, reduces time to market, and enables companies to effectively implement ML strategies at any scale—from R&D to mass production.
Cloud AI/ML Service – An Optimised Platform for MLOps
In modern machine learning architectures, the AI cloud service acts as a centralized, managed platform focused on providing the complete lifecycle of ML models - from data collection and processing to deployment, monitoring, and automatic updates. Such a service forms the foundation for implementing MLOps practices that standardise the process of developing, deploying, and supporting models in a production environment.
The main advantage of the ML service is the ability to automate complex tasks through pipelines: data transformation, hyperparameter search, distributed training, quality assurance, and deployment on an inference infrastructure with autoscaling and SLA monitoring. Most solutions are implemented using a microservice architecture with REST/gRPC API support, which simplifies integration with other system components.
The machine learning service also enables centralized management of metadata, artifacts, and model and data versions, ensuring reproducibility and traceability of all changes. By integrating with CI/CD systems, it becomes possible to implement model quality control at each stage of deployment — featuring automatic testing, rollback to previous versions, and promotion of changes through environments. A cloud-based machine learning service typically supports various types of computation — batch, stream, and real-time inference — and dynamically scales through containerization, serverless computing, or cluster computing. This approach reduces latency for critical tasks (such as anomaly detection in cybersecurity systems or recommender systems) and lowers operating costs by optimizing resources during downtime.
Built-in monitoring and observation functions (observability) allow you to control not only technical indicators (latency, error rate) but also specific ML metrics — accuracy, precision, recall, drift, and confidence distribution. In combination with automated retraining triggers, this helps you maintain models in a valid state even under conditions of dynamic data change.
Modern cloud ML services also account for security and access control requirements: RBAC, audit trails, encryption of artifacts and secrets, and data governance policies. This is critically important for corporate scenarios where solutions handle personal or commercially sensitive data.
Ultimately, an AI cloud service is not just a computing platform, but a comprehensive technology stack configured to implement a continuous machine learning cycle. Its scalability, automation, and integration with modern DevOps approaches enable teams to quickly launch, test, adapt, and maintain AI solutions in a production-ready environment.
ML as a Service – who is it suitable for and how to choose a provider?
ML as a Service (MLaaS) is a model for delivering machine learning tools as a cloud service, enabling companies to build, train, deploy, and scale models without the need to manage complex infrastructure. This approach is particularly valuable for teams that wish to concentrate on solving business problems rather than on building and maintaining internal AI/ML platforms.
AI ML services are suitable for:
- startups and small teams that lack their own DevOps or MLOps specialists;
- enterprises that want to quickly test a hypothesis or MVP without investing in hardware;
- large companies as part of a hybrid strategy, for example, for non-critical models, data processing outside the main data center, or edge inference.
When choosing an AI/ML service provider, there are several critical aspects to consider:
1. Scalability and type of computing resources: It is important to have access to GPU/TPU, autoscaling clusters, as well as the ability to perform both batch and real-time inference.
2. MLOps support: Model and data versioning, CI/CD pipelines, rollback, testing, environment promotion, and observability (metrics, logging, alerts).
3. API and SDK flexibility: Availability of REST/gRPC support, integration with popular ML frameworks, support for custom containers and runtime environments.
4. Security and compliance: RBAC, encryption, audit logs, and access control to confidential data—especially important for regulated industries.
5. Cost and billing model: Transparency of pricing, pay-as-you-go, and the ability to predict the cost of pipelines in advance.
Modern AI and ML services often include additional features: AutoML, Data Labeling, Feature Store, and Model Registry — all of which reduce development time and enhance team productivity. Overall, ML as a Service is the ideal choice for organizations aiming to quickly scale AI initiatives without compromising reliability and quality. The key is to thoroughly understand your technology, security, performance, and maintenance requirements to select a service that not only “works,” but also fully aligns with the goals and architecture of your AI solution.
Managing ML Models: How to Control the Machine Learning Lifecycle in the Cloud?
In the cloud, managing ML models extends well beyond training. It is a thorough process that includes all phases of the lifecycle, from prototyping to monitoring performance in production and scheduled retraining. Effectively managing ML models ensures quality control, operational stability, and scalability of AI systems.
In practice, ML management involves:
- Versioning models, datasets, code, and configurations to ensure full reproducibility and trace sources of errors;
- Registration and control of artifacts, storage of metadata, and experiment results;
- Orchestration of ML pipelines using a DAG/DSL description of stages: data processing, training, validation, deployment, and testing;
- CI/CD for ML, including automatic deployment of models to staging and production environments;
- Performance monitoring, which includes inference latency, throughput, accuracy, precision metrics, and control of drift metrics (data and concept drift);
- Alerting and retraining triggers that launch retraining in response to model degradation or changing input data characteristics;
- Role-based access control (RBAC), audit logging, and automatic application of security and management policies (policy enforcement) — for access control, audit logging, and compliance.
A typical ML model management solution in the cloud is implemented through a combination of containerized environments (Kubernetes), a pipeline engine (Airflow, Argo), a model registry, loggers, and tracking systems. This approach allows for centralized management of hundreds of models running simultaneously across multiple business domains. Consequently, ML management in the cloud is not merely a set of startup utilities, but a comprehensive strategy for scaling AI solutions with guaranteed control, stability, and adaptability under varying workloads and data dynamics.
How can we ensure the optimization, stability, and scalability of models in the cloud for MLOps?
To ensure the efficient operation of AI systems in the cloud, it is critical to implement a robust MLOps architecture in the cloud (MLOps Cloud). This means that all stages of the model lifecycle — from training to deployment, monitoring, and retraining — must be automated, controlled, and scalable. Optimization is achieved through the use of containerization, autoscaling of computing resources, including GPU/TPU clusters, and efficient orchestration systems — such as pipeline engines.
The cloud for MLOps enables you to dynamically adapt the infrastructure to changes in load and flexibly distribute calculations between nodes, which enhances resource efficiency. Stability is ensured through continuous integration and deployment (CI/CD) pipelines, automatic health-checking, model quality control (accuracy, latency, data drift), rollback mechanisms, and alerting.
Scaling is implemented both vertically—by increasing resource capacity—and horizontally, through the parallel deployment of models in different regions, a modular pipeline architecture, and support for multiple models at the same time (multi-model serving). In short, MLOps in the cloud is an adaptive infrastructure that enables you to quickly implement, scale, and monitor machine learning models at every stage of their lifecycle in a production environment.