





AI/ML платформа для для запуску, тренування та інференсу AI/ML моделей
Готове середовище для роботи з машинним навчанням — без зайвих витрат часу на налаштування інфраструктури, яке розгорнуте у хмарі з NVIDIA GPU.
ML Cloud поєднує інтегровану, попередньо сконфігуровану й самодостатню збірку «best of breed» з open source MLOps-інструментів та акселератори NVIDIA H200 NVL / H100 / A100 NVL / L40s / L4.
Готове до використання робоче середовище ML-інженера – це значне зниження порогу входу до світу AI/ML. А новітні тензорні акселератори NVIDIA забезпечують недосяжну для інших технологій продуктивність на задачах машинного навчання та продуктивного інференсу.
Просто заходьте і починайте тренувати, деплоїти або робити інференс моделей — без зайвого клопоту.

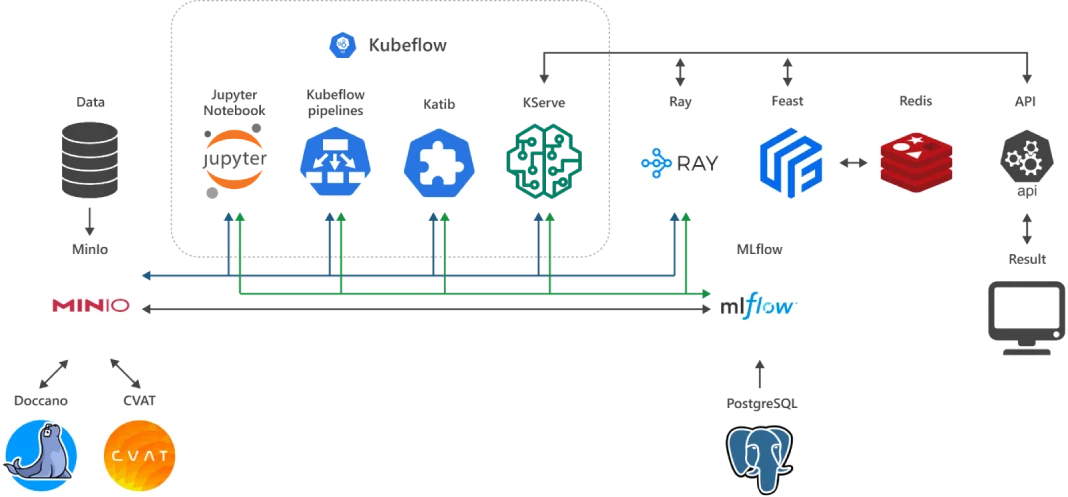
З чого складається ML Cloud?
Тестування 14 днів безкоштовно
Продукти для AI/ML

Готове середовище, у якому можна створювати власні застосунки з генеративним ШІ, тестувати їх і безпечно підключати до бізнес-процесів. Платформа підтримує підхід low-code/no-code

Дозволяє швидко розгорнути модель, підключити корпоративні дані, протестувати сценарії, запустити інференс і безпечно інтегрувати Gen AI в бізнес-процеси

Хмара з Kubernetes та NVIDIA GPU H200 NVL, H100, A100 NVL, L40S, L4 з тензорними ядрами для запуску робочих навантажень штучного інтелекту та машинного навчання (AI/ML) в колективній хмарі De Novo

Акселерований для AI/ML Kubernetes з NVIDIA GPU H200 NVL, H100, A100 NVL, L40S, L4 з тензорними ядрами на базі приватної хмари Hosted Private Infrastructure (HPI)
Як працюють сучасні AI-рішення від хмарних провайдерів?
У сучасній ІТ-інфраструктурі AI рішення у хмарі стали фундаментом для масштабованих, продуктивних і гнучких систем, які здатні розв’язувати складні задачі з обробки даних, автоматизації й аналітики. Основна ідея — перенесення обчислювального навантаження та моделей штучного інтелекту на хмарні платформи, де ресурси масштабуються динамічно, а розробка й впровадження значно спрощуються.
Типова архітектура передових AI рішень у хмарі базується на мікросервісному підході, контейнеризації (Docker, Kubernetes) та використанні спеціалізованих обчислювальних ресурсів — прискорювачів GPU, TPU або FPGA, доступних через інтерфейси провайдерів. Такі технологічні рішення AI включають в себе сервіси для попередньої обробки даних (data pipelines), автоматизованого машинного навчання (AutoML), управління експериментами, а також CI/CD для ML-моделей.
Хмарні провайдери AI рішень інтегрують найсучасніші фреймворки (TensorFlow, PyTorch, ONNX) і підтримують serverless-парадигму у контексті inference-функцій, що дозволяє запускати моделі на запит без потреби у виділеній інфраструктурі. Це особливо актуально для сценаріїв з високою динамікою навантаження — наприклад, в e-commerce, фінансових аналітичних системах чи в real-time обробці зображень і відео.
Ключова перевага AI у хмарі — це можливість масштабування й зниження бар’єру входу: замість витрат на власне GPU-обладнання компанії можуть використовувати потужності провайдера й сплачувати лише за фактичне використання ресурсів. Це особливо вигідно для стартапів або R&D-відділів, які активно експериментують з різними рішеннями штучного інтелекту. Інтеграція artificial intelligence у хмарі також передбачає глибоку підтримку DevOps- і MLOps-практик: автоматичне логування результатів, контроль версій , безперервне тестування, а також інтеграцію з корпоративними системами даних (Data Lake, DWH, API). Завдяки цьому розробники можуть зосередитися на логіці моделі, не витрачаючи час на налаштування інфраструктури.
Отже, AI рішення у хмарі — це не просто сервіс для запуску моделей, а повноцінна екосистема, яка охоплює всі етапи життєвого циклу AI-продукту: від збирання даних до розгортання й моніторингу в продакшн-середовищі. Такі передові AI рішення формують основу нової хвилі цифрової трансформації, дозволяючи бізнесу швидше приймати рішення, ефективніше працювати з даними та створювати інноваційні сервіси на основі штучного інтелекту.
Які переваги хмарного машинного навчання?
Хмарне машинне навчання (MLaaS) стало ключовою складовою сучасної data science-екосистеми, забезпечуючи розробників, аналітиків та інженерів гнучкими, масштабованими й економічно ефективними інструментами. Завдяки розподіленій природі хмарних середовищ, машинне навчання в хмарі дозволяє уникнути капітальних витрат на фізичну інфраструктуру й забезпечує on-demand доступ до GPU, TPU та інших спеціалізованих обчислювальних ресурсів.
Однією з основних переваг є масштабованість: хмара для машинного навчання дозволяє паралелізувати тренування , використовуючи автоматичне масштабування і розподілене навчання. Це критично важливо для великих датасетів або deep learning-архітектур. Також спрощується управління ресурсами через інфраструктуру як код (IaC) та контейнеризацію (наприклад, запуск у Kubernetes-кластерах чи serverless-середовищах). Важливою характеристикою ml cloud є інтеграція з інструментами MLOps: контроль версій даних і моделей, CI/CD пайплайни, автоматизоване тестування і моніторинг в реальному часі. Це дозволяє підтримувати високу якість ПЗ на етапі inference, а також оперативно реагувати на data drift чи зміну патернів у вхідних даних.
Крім того, машинне навчання в хмарі значно спрощує взаємодію в командах: спільне використання артефактів, модульна структура пайплайнів, ізольовані середовища тестування, валідації й продакшн-деплойменту. Це особливо важливо для сценаріїв з CI/CD та agile-розробкою в багатофункціональних командах. Загалом, хмарне машинне навчання забезпечує ефективне середовище для швидкого прототипування, експериментування, масштабування й супроводу програмної розробки на всіх етапах життєвого циклу — від raw-даних до стабільного продакшну з високою доступністю.
Як хмарні обчислення пришвидшують розвиток AI та ML?
Хмарні обчислення AI відіграють ключову роль у масштабуванні, продуктивності й доступності штучного інтелекту, особливо в умовах стрімкого зростання обсягів даних і складності рішення. Традиційна on-premise інфраструктура часто не здатна забезпечити необхідну обчислювальну потужність і гнучкість, які потрібні для сучасних моделей deep learning, reinforcement learning або LLM. Натомість хмарні обчислення штучного інтелекту дозволяють миттєво отримувати доступ до високопродуктивних кластерів GPU/TPU, масштабованих сховищ і керованих сервісів автоматизації всього життєвого циклу ML/AI проєктів.
Завдяки розподіленим обчисленням і вбудованій підтримці контейнеризації (Kubernetes, Docker) artificial intelligence у хмарі може тренуватися в паралельному режимі з використанням стратегій, як-от data parallelism, model parallelism або hybrid training, що суттєво зменшує час навчання, наприклад LLM. Це критично важливо для задач машинного зору (computer vision), NLP або обробки часових рядів (time series), де тренування на локальній інфраструктурі може тривати днями або тижнями.
Крім обчислювальних переваг, хмарні обчислення та штучний інтелект тісно інтегруються на рівні автоматизації. Сучасні ML-стекі в хмарі включають повну підтримку MLOps: автоматичний deployment моделей, контроль версій артефактів, моніторинг затримки відповіді моделі (inference latency), data drift і SLA, а також CI/CD пайплайни ради оновлення без простою. Це забезпечує швидкий перехід від прототипів до production-рішень.
З точки зору архітектури, machine learning у хмарних обчисленнях використовує інфраструктуру як код (IaC), serverless-технології та event-driven підходи (наприклад, запуск пайплайнів за тригерами з message-брокерів чи об’єктних сховищ). Це дозволяє зменшити операційні витрати й підвищити надійність системи, а також дає змогу гнучко масштабувати ресурси в залежності від потреб кожного етапу пайплайну — від data ingestion до онлайн inference.
Крім того, хмарні обчислення для machine learning спрощують управління даними: інтеграція з Data Lake, feature store, data warehouse й stream-інфраструктурою дозволяє централізовано зберігати, обробляти і подавати дані до моделей. Це забезпечує консистентність, traceability і відповідність політикам безпеки і доступу. У результаті хмарні обчислення AI не лише зменшують бар’єр входу в розробку технології, а й формують середовище, в якому AI/ML-проєкти можна масштабувати з лабораторного прототипу до глобального продакшну з високим навантаженням, SLA та fault tolerance.
Хмарна платформа для AI – інфраструктура, яка масштабується разом із потребами
Сучасна хмарна AI платформа є ключовим елементом масштабованої AI-екосистеми, що дозволяє компаніям реалізовувати повноцінні пайплайни машинного навчання без необхідності будувати складну інфраструктуру з нуля. Така платформа забезпечує керування повним життєвим циклом розрбки: від збору й попередньої обробки даних до навчання, валідації, деплойменту, моніторингу та переобучення.
Основна перевага, яку дає хмарна платформа для AI, — це автоматизоване масштабування обчислювальних ресурсів у відповідь на зміну навантаження. Наприклад, під час масового тренування моделей або виконання resource-intensive задач (як-от гіперпараметричний пошук або distributed training) обчислювальні ресурси масштабуються горизонтально з використанням GPU/TPU кластерів. У періоди низької активності інфраструктура автоматично згортається, знижуючи витрати.
AI платформа на основі хмари реалізована на базі мікросервісної й подійно-орієнтованої архітектури з глибокою інтеграцією DevOps- та MLOps-практик. Інфраструктура описується декларативно через IaC (Terraform, Pulumi), пайплайни автоматизуються через workflow-движки (Argo, Airflow), а деплоймент здійснюється з використанням container registry, policy-based promotion і автоматичного тестування якості (validation hooks, integration tests).
Хмарна платформа штучного інтелекту також включає керовані сервіси для зберігання артефактів, історії тренувань, логів, метрик, а також реалізує повноцінне спостереження (observability) — з моніторингом latency, throughput, error rate та зміни розподілу вхідних даних (concept/data drift). Це дозволяє оперативно виявляти деградацію продуктивності моделей у продакшн-середовищі.
Особливістю хмарної AI платформи є її готовність до гібридних і мульти-регіональних сценаріїв. Платформи підтримують як централізоване, так і edge-розгортання моделей — з можливістю синхронізації конфігурацій, автоматичного оновлення інференс-агентів і агрегації телеметрії в основну платформу. Таким чином, хмарна платформа для AI дозволяє інженерним командам зосередитися на якості моделі та швидкості інновацій, не витрачаючи час на обслуговування інфраструктури. Її масштабованість, модульність й автоматизація роблять її ключовим інструментом для будь-якого підприємства, що прагне інтегрувати AI у свої продукти чи сервіси на рівні продакшну.
Що таке платформа для машинного навчання і як вона працює?
Платформа для машинного навчання — це комплексне програмно-апаратне середовище, призначене для автоматизації всіх етапів побудови, розгортання й супроводу машинного навчання. Така платформа слугує центральною точкою для дата-інженерів, дата-сайєнтистів, MLOps-інженерів та розробників, забезпечуючи спільну роботу над даними, кодом, експериментами і продакшн-рішеннями.
З технічного погляду, платформа машинного навчання реалізує повний життєвий цикл розробки — від підготовки даних до експлуатації (інференсу, inference) — у вигляді модульної архітектури. До її основних компонентів входять:
- середовище обробки та трансформації даних (ETL, feature engineering);
- сховище датасетів, артефактів і моделей (object storage, model registry);
- інструменти експериментування (ноутбуки, інтерфейси для запуску тренувань);
- механізми автоматичного тренування, гіперпараметричного пошуку й валідації;
- пайплайни деплойменту моделей (CI/CD, canary/staged rollout);
- модулі моніторингу продуктивності (latency, accuracy, drift detection).
У центрі системи — платформа ML, яка координує виконання цих процесів за допомогою task scheduler’ів, систем оркестрації декларативного опису workflow (наприклад, через YAML чи DSL). Це дозволяє автоматизувати запуск пайплайнів, контролювати залежності між задачами й забезпечувати відтворюваність експериментів.
Платформа AI ML тісно інтегрується з DevOps- і MLOps-інструментами: від контролю версій моделей й метаданих (MLflow, DVC), до логування та телеметрії в інференс-середовищі. Завдяки цьому розробники можуть не тільки створювати моделі, а й підтримувати їхню якість на протязі всього життєвого циклу. Ключовою особливістю є масштабованість: платформа AI адаптується до потреб задачі — чи то batch-обробка великих обсягів даних, чи inference у реальному часі на edge-пристроях. З цією метою цього вона використовується динамічне керування обчислювальними ресурсами, автоматичний autoscaling, підтримку GPU/TPU і контейнеризоване виконання.
Також важливу роль відіграє безпека та контроль доступу: платформа для штучного інтелекту реалізує багаторівневу автентифікацію, RBAC, audit-логи й політики управління даними — особливо важливо для регульованих галузей, де критичною є прозорість і відтворюваність ML-рішень. У підсумку, платформа для машинного навчання — це не просто інструмент для тренування, а стратегічна інфраструктура для створення, масштабування й підтримки AI-систем. Вона забезпечує стандартизацію процесів, скорочує час виходу на ринок і дає змогу компаніям ефективно реалізовувати ML-стратегії у будь-якому масштабі — від R&D до масового продакшну.
Хмарний AI/ML сервіс – оптимізована платформа для MLOps
У сучасних архітектурах машинного навчання хмарний сервіс AI виступає як централізована керована платформа, орієнтована на забезпечення повного життєвого циклу ML-моделей – від збирання й обробки даних до деплойменту, моніторингу та автоматичного оновлення. Такий сервіс є основою для впровадження MLOps-практик, що дозволяють стандартизувати процес розробки, розгортання і підтримки моделей у продакшн-середовищі.
Основна перевага, яку дає ml сервіс, полягає у можливості автоматизації складних задач через пайплайни: трансформація даних, гіперпараметричний пошук, тренування у розподіленому режимі, перевірка якості й розгортання на інференс-інфраструктурі з автомасштабуванням та моніторингом SLA. Більшість рішень реалізовані у вигляді мікросервісної архітектури з підтримкою REST/gRPC API, що спрощує інтеграцію з іншими компонентами системи.
Сервіс машинного навчання також дозволяє централізовано керувати метаданими, артефактами, версіями моделей й даних, забезпечуючи відтворюваність (reproducibility) та простежуваність (traceability) усіх змін. Через інтеграцію з CI/CD-системами можливо реалізувати контроль якості моделей на кожному етапі розгортання — з автоматичним тестуванням, відкатом до попередніх версій (rollback) і просуванням змін через середовища (environment promotion).
Хмарний сервіс машинного навчання зазвичай підтримує різні типи обчислень — batch, stream, real-time inference — і динамічно масштабується завдяки використанню контейнеризації, бессерверних (serverless) або кластерних обчислень. Це дозволяє зменшити затримку для критичних задач (наприклад, в під час виявлення аномалій у системах кібербезпеки чи рекомендаційних системах) й знизити вартість експлуатації через оптимізацію ресурсів під час простою.
Вбудовані функції моніторингу та спостереження (observability) дозволяють контролювати не лише технічні показники (latency, error rate), а й специфічні ML-метрики — accuracy, precision, recall, drift, confidence distribution. У поєднанні з автоматизованими трігерами переобучення це дає змогу підтримувати моделі у валідному стані навіть в умовах динамічної зміни даних.
Сучасні хмарні ML-сервіси також враховують вимоги безпеки й контролю доступу: RBAC, audit-треки, шифрування артефактів і секретів, політики data governance. Це критично важливо для корпоративних сценаріїв, де рішення працюють з персональними або комерційно чутливими даними.
У підсумку, хмарний сервіс AI — це не просто обчислювальна платформа, а повноцінний технологічний стек налаштований на процес реалізації безперервного циклу машинного навчання. Його масштабованість, автоматизованість й інтеграція з сучасними DevOps-підходами дозволяють командам швидко запускати, тестувати, адаптувати й підтримувати AI-рішення у production-ready середовищі.
ML as a Service – кому підходить і як обрати провайдера?
ML as a Service (MLaaS) — це модель надання інструментів машинного навчання як хмарної послуги, що дозволяє компаніям створювати, тренувати, розгортати та масштабувати моделі без потреби в управлінні складною інфраструктурою. Такий підхід особливо цінний для команд, які хочуть зосередитися на розв’язанні бізнес-задач, а не на побудові й підтримці внутрішніх AI/ML платформ.
Послуга AI ML підходить:
- стартапам і невеликим командам, які не мають власних DevOps або MLOps-фахівців;
- підприємствам, що прагнуть швидко протестувати гіпотезу або MVP без інвестицій у хардвар;
- великим компаніям — як частина гібридної стратегії, наприклад, для non-critical моделей, обробки даних поза межами основного дата-центру або edge inference.
При виборі провайдера послуг AI ML слід враховувати кілька критичних аспектів:
- Масштабованість й тип обчислювальних ресурсів: важливо мати доступ до GPU/TPU, autoscaling-кластерів, а також можливість виконання як batch-, так і real-time inference.
- Підтримка MLOps: версіонування моделей і даних, CI/CD пайплайни, rollback, тестування, environment promotion, а також observability (метрики, логування, алерти).
- Гнучкість API і SDK: наявність підтримки REST/gRPC, інтеграція з популярними ML-фреймворками, підтримка кастомних контейнерів і runtime-середовищ.
- Безпека та відповідність: RBAC, шифрування, audit logs, контроль доступу до конфіденційних даних — особливо важливо для regulated industries.
- Вартість і модель білінгу: прозорість ціноутворення, оплата за використання (pay-as-you-go), можливість попереднього прогнозування вартості пайплайнів.
Сучасні послуги AI та ML часто включають додаткові сервіси: AutoML, Data Labeling, Feature Store, Model Registry — усе це скорочує час розробки й підвищує продуктивність команд.
Загалом, ML as a Service — це оптимальний варіант для організацій, які хочуть швидко масштабувати AI-ініціативи, не жертвуючи надійністю і якістю. Головне — чітко розуміти свої вимоги до технології, безпеки, продуктивності й обслуговування, щоби обрати сервіс, який не лише «працює», а повністю відповідає цілям та архітектурі вашого AI-рішення.
Управління ML-моделями – як контролювати життєвий цикл машинного навчання у хмарі?
У хмарному середовищі управління ML-моделями виходить далеко за межі етапу їх тренування. Це комплексний процес, який охоплює всі фази життєвого циклу — від створення прототипу до моніторингу продуктивності в продакшні і планового перенавчання. Ефективне управління моделями ML забезпечує контроль якості, стабільність роботи й можливість масштабування AI-систем.
На практиці ML management передбачає:
- Версіонування (Versioning) моделей, датасетів, коду і конфігурацій — з метою забезпечення повної відтворюваності (reproducibility) та трасування джерел помилок;
- Реєстрацію та контроль артефактів, зберігання метаданих і результатів експериментів;
- Оркестрацію ML-пайплайнів із використанням DAG/DSL-опису етапів: обробка даних, тренування, валідація, деплоймент, тестування;
- CI/CD для ML, включаючи автоматичне розгортання моделей на staging та production середовищах;
- Моніторинг продуктивності: метрики inference latency, throughput, accuracy, precision, а також контроль drift-метрик (data і concept drift);
- Cповіщення (Alerting) і тригери переобучення, які запускають retraining у відповідь на деградацію моделі або зміну характеристик вхідних даних;
- Контроль доступу на основі ролей (RBAC), ведення журналу дій (Audit), автоматичне застосування політик безпеки й керування (policy enforcement) — з метою контролю доступу, журналювання дій й відповідності нормативним вимогам.
Типове ML model management-рішення в хмарі реалізується через комбінацію контейнеризованих середовищ (Kubernetes), системи виконання послідовності задач — pipeline engine (Airflow, Argo), модельного реєстру, логерів й трекінгових систем. Це дозволяє централізовано керувати сотнями моделей, що одночасно функціонують у різних бізнес-доменах. У результаті управління ML у хмарі — це не просто набір утиліт запуску, а повноцінна стратегія масштабування AI-рішень з гарантією контролю, стабільності та адаптивності в умовах змінного навантаження і динаміки даних.
Як забезпечити оптимізацію, стабільність і масштабування моделей у хмарі для MLOps?
Для забезпечення ефективної роботи AI-систем у хмарному середовищі критично важливо впровадити надійну архітектуру MLOps у хмарі (MLOps Cloud). Це означає, що всі етапи життєвого циклу моделі — від тренування до розгортання, моніторингу й переобучення — мають бути автоматизовані, контрольовані та здатні до масштабування. Оптимізація досягається через використання контейнеризації, автоматичного масштабування (autoscaling) обчислювальних ресурсів, зокрема GPU/TPU-кластерів і ефективних систем оркестрації — таких, як планувальники робочих процесів (pipeline engines).
Хмара для MLOps дає змогу динамічно адаптувати інфраструктуру до змін навантаження і гнучко розподіляти обчислення між вузлами, що підвищує ефективність використання ресурсів.
Стабільність забезпечується через конвеєри безперервної інтеграції та розгортання (CI/CD), автоматичну перевірку працездатності (health-check), контроль якості моделей (точність, затримка, зміщення даних — data drift), механізми швидкого повернення до попередньої версії (rollback) й систему сповіщень (alerting).
Масштабування реалізується як вертикально (збільшення потужності ресурсів), так і горизонтально — через паралельне розгортання моделей у різних регіонах, модульну архітектуру пайплайнів і підтримку декількох моделей одночасно (multi-model serving). У підсумку, MLOps у хмарі — це адаптивна інфраструктура, що дозволяє швидко впроваджувати, масштабувати і контролювати моделі машинного навчання на кожному етапі їхнього життєвого циклу в продакшн-середовищі.