






Самые современные ускорители NVIDIA H200 доступны в облаке De Novo
2025-12-16

De Novo объявляет о доступности для пользователей NVIDIA H200 — наиболее производительных тензорных ускорителей с объемом памяти 141 ГБ, пропускной способностью 4,8 ТБ/с и стековой памятью HBM3e для больших языковых моделей (LLM). Это самое современное решение для задач генеративного искусственного интеллекта (GenAI), которое теперь доступно в украинском облаке.
Вместе с ускорителями NVIDIA H100, A100, L40S и L4 новые карты H200 формируют самую масштабную GPU-инфраструктуру в стране, позволяя бизнесу обучать сложные ИИ-модели без передачи данных за границу. Ключевое преимущество H200 — это не просто «большая мощность», а революционная подсистема с использованием высокоскоростной стековой памяти HBM3e. Ранее развитие ИИ сдерживала именно скорость обмена данными, а не вычислительная мощность процессоров. Новые карты устраняют этот барьер, позволяя обрабатывать значительно большие объёмы информации для ИИ-моделей.
Технические характеристики в цифрах
• Пропускная способность подсистемы памяти: 4,8 ТБ/с (на 43% быстрее по сравнению с H100).
• Объём памяти: 141 ГБ (на 76% больше, чем у H100).
• Эффективность: время обработки запросов (инференс) моделями уровня Llama 3 70B ускоряется до +50%.
Благодаря увеличенному объёму памяти большие языковые модели (LLM) теперь могут работать на одной видеокарте без необходимости шардирования (разделения задачи на части), что существенно повышает производительность.

Новый высокоскоростной коммуникационный интерфейс NVIDIA NVLink четвёртого поколения с пропускной способностью до 900 ГБ/с позволяет объединять до восьми ускорителей H200 в единый вычислительный узел с общим пулом памяти более 1,1 ТБ. Это открывает новые горизонты, позволяя украинским компаниям решать сверхсложные задачи.
Сравнение H200 с другими моделями
Разработчикам и AI командам важно четко понимать разницу между GPU-ускорителями. Выбор зависит от задачи: генерация, инференс, fine-tuning, мультимодальные вычисления или построение RAG-систем. Ключевые отличия между H200 и другими картами – в пропускной способности памяти, объеме HBM и возможности запуска моделей уровня Llama 3 70B без шардирования. В то время как H100 – стандарт для LLM 2023 года, H200 уже оптимизирован под новое поколение моделей с более длинным контекстом и более высокой плотностью параметров.
| Модель | Архитектура | Поколение тензорных ядер | Тип памяти | Обьем памяти | Пропускная способность памяти, макс. | NVLink | Версия PCIe | Оптимальный сценарий |
| H200 | Hopper | 4-е | HBM3 | 141 ГБ | 4,8 ТБ/с | 4.0 | 5.0 | LLM 70B+, RAG, мультимодальность |
| H100 | Hopper | 4-е | HBM3 | 80 ГБ | 3,35 ТБ/с | 4.0 | 5.0 | LLM 65B, инференс и тренировка |
| A100 | Ampere | 3-е | HBM2e | 80 ГБ | 2 ТБ/с | 3.0 | 4.0 | Обучение середних моделей |
| L40S | Ada Lovelace | 4-е | GDDR6 | 48 ГБ | 864 ГБ/с | – | 4.0 | Инференс в продакшене |
| L4 | Ada Lovelace | 4-е | GDDR6 | 24 ГБ | 300 ГБ/с | – | 4.0 | легкий инференс, API |
Для задач генеративного ИИ с моделями более 60 млрд параметров именно H200 обеспечивает наибольшую производительность и гибкость. Благодаря увеличенному объему HBM3e и ускорению подсистемы памяти в целом H200 позволяет избегать шардирования и выполнять полноценный инференс «на одной карте». Это упрощает архитектуру приложений, сокращает задержки и потребление энергии.
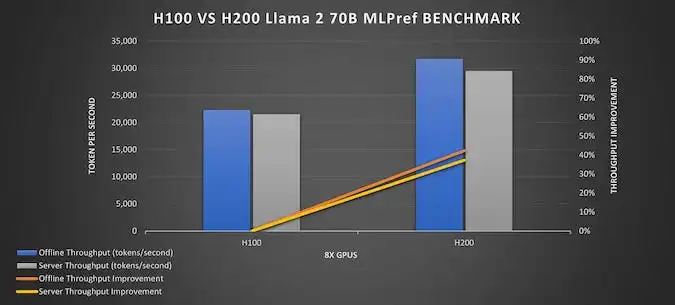
В свою очередь, H100 остается мощной опцией для тонкой настройки или дообучения (fine-tuning) моделей или задач с меньшим контекстом. L40S или L4 — эффективны для высоконагруженных inference‑сценариев в продуктивной среде, когда время ответа критическое, но ресурсы ограничены.
В облаке De Novo все карты доступны как отдельно, так и в виде кластеров с NVLink (там, где эта технология поддерживается). Это позволяет выбирать оптимальную конфигурацию под каждый проект.
Цена и доступность в облаке De Novo
Ускорители NVIDIA H200 позволяют инженерам и командам AI получить максимальную вычислительную мощность без инвестиций в собственную инфраструктуру. Цена NVIDIA H200 в почасовой аренде составляет $5,08 за полную мощность карты. Также доступны конфигурации аренды части ресурсов:
- NVIDIA H200 NVL = $5,08/час;
- ½ NVIDIA H200 NVL = $2,54/час;
- ¼ NVIDIA H200 NVL = $1,27/час;
- ⅛ NVIDIA H200 NVL = $0,63/час.
Это позволяет оптимизировать бюджеты и вычислительные ресурсы под конкретные задачи и нагрузки.
Где H200 подойдут лучше всего
В области генеративного AI (GenAI) H200 идеально подходят для создания высокоточных RAG-систем, работающих с закрытыми корпоративными базами знаний, например для автоматизации юридического анализа, обработки медицинских данных или создания технической документации. Также такие мощности критически важны для обучения масштабных LLM с миллиардами параметров и создания высокопроизводительных чат-ботов или рекомендательных систем.

Для пользователей, работающих с LLM и инференсом в средах разработки и продакшена, в GPU облаке De Novo доступна платформа AI Studio — предварительно настроенная среда для запуска и оптимизации моделей. AI Studio предлагает готовые контейнерные окружения с поддержкой CUDA, PyTorch, TensorRT, векторных баз данных и инструментов для RAG-систем. Благодаря интегрированным API разработчики могут быстро разворачивать модели на H200 без ручной подготовки инфраструктуры, сосредоточившись непосредственно на продукте, а не на настройках.
Все вычисления выполняются в защищённом облаке De Novo (сертификаты ISO 27001, PCI DSS, КСЗИ), что гарантирует юридическую чистоту данных. Новые карты полностью совместимы с популярными инструментами (CUDA, PyTorch, Kubernetes), что позволяет разработчикам мгновенно получить прирост производительности без перестройки IT-инфраструктуры. Таким образом, H200 в облаке De Novo — это инструмент, который позволяет украинским компаниям войти в новую эру мультимодальных и генеративных моделей и повысить конкурентоспособность на глобальном рынке ИИ.