






The latest NVIDIA H200 accelerators are available in the De Novo cloud
2025-12-16

De Novo announces the availability of NVIDIA H200, the most powerful tensor accelerators with 141 GB of memory, 4.8 TB/s bandwidth, and HBM3e stacked memory for large language models (LLMs). This is the most advanced solution for generative artificial intelligence (GenAI) tasks, now available in the Ukrainian cloud.
Together with NVIDIA H100, A100, L40S, and L4 accelerators, the new H200 cards form the most extensive GPU infrastructure in the country, allowing businesses to train complex AI models without transferring data abroad. The key advantage of the H200 is not just “more power,” but a revolutionary subsystem using high-speed HBM3e stacked memory. Previously, AI development was held back by data transfer speeds rather than processor power. The new cards remove this barrier, allowing significantly larger amounts of information to be processed for AI models.
Technical specifications in numbers
- Memory subsystem bandwidth: 4.8 TB/s (43% faster than its predecessor, the H100).
- Memory capacity: 141 GB (76% more than the H100).
- Efficiency: Request processing time (inference) with Llama 3 70B models is accelerated by up to +50%.
Thanks to the increased memory capacity, large language models (LLMs) can now run on a single graphics card without the need for sharding (dividing the task into parts), which significantly improves performance.

The new fourth-generation NVIDIA NVLink high-speed communication interface, with a bandwidth of up to 900 GB/s, allows up to eight H200 accelerators to be combined into a single computing node with a total memory pool of over 1.1 TB. This opens up new horizons, allowing Ukrainian companies to solve extremely complex tasks.
Comparing H200 with other models
It is important for developers and AI teams to clearly understand the difference between GPU accelerators. The choice depends on the task: generation, inference, fine-tuning, multimodal computing, or building RAG systems. The key differences between the H200 and other cards are in memory bandwidth, HBM capacity, and the ability to run Llama 3 70B-level models without sharding. While H100 is the standard for LLM 2023, H200 is already optimized for a new generation of models with longer context and higher parameter density.
| Model | Architecture | Generation of tensor cores | Memory type | Memory capacity | Memory bandwidth, max. | NVLink | PCIe version | Optimal scenario |
| H200 | Hopper | 4-е | HBM3 | 141 GB | 4,8 TB/s | 4.0 | 5.0 | LLM 70B+, RAG, multimodality |
| H100 | Hopper | 4-е | HBM3 | 80 GB | 3,35 TB/s | 4.0 | 5.0 | LLM 65B, training and inference |
| A100 | Ampere | 3-є | HBM2e | 80 GB | 2 TB/s | 3.0 | 4.0 | Training medium models |
| L40S | Ada Lovelace | 4-е | GDDR6 | 48 GB | 864 GB/s | – | 4.0 | Productive inference |
| L4 | Ada Lovelace | 4-е | GDDR6 | 24 GB | 300 GB/s | – | 4.0 | Lightweight inference, API |
For generative AI tasks with models exceeding 60 billion parameters, the H200 delivers the highest performance and flexibility. With increased HBM3e capacity and accelerated memory subsystem overall, the H200 avoids sharding and enables full inference on a single card. This simplifies application architecture, reduces latency, and lowers power consumption.
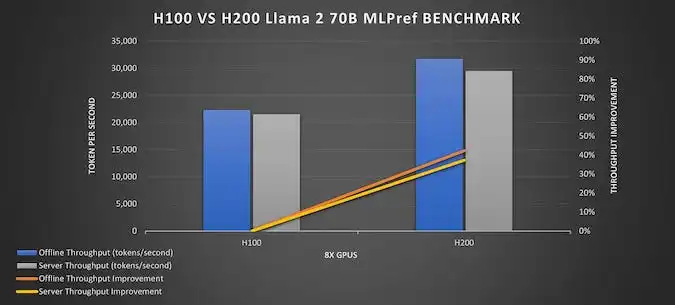
Meanwhile, H100 remains a powerful option for fine-tuning and retraining models or tasks with less context. L40S or L4 are effective for high-load inference scenarios in a productive environment where response time is critical but resources are limited.
In the De Novo cloud, all of these cards are available individually or in clusters with NVLink (where this technology is supported). This allows you to choose the optimal configuration for each project.
Price and availability in the De Novo cloud
NVIDIA H200 accelerators allow engineers and AI teams to get maximum computing power without investing in their own infrastructure. The price of NVIDIA H200 on an hourly rental basis is $5.08 for full card power. Partial resource rental configurations are also available:
- NVIDIA H200 NVL = $5.08/hour;
- ½ NVIDIA H200 NVL = $2.54/hour;
- ¼ NVIDIA H200 NVL = $1.27/hour;
- ⅛ NVIDIA H200 NVL = $0.63/hour.
This allows you to optimize budgets and computing resources for specific tasks and workloads.
Where H200s are best suited
In the field of generative AI (GenAI), H200s are ideal for creating highly accurate RAG systems that work with closed corporate knowledge bases, for example, to automate legal analysis, process medical data, or create technical documentation. Such capabilities are also critical for training large-scale LLMs with billions of parameters and creating high-performance chatbots or recommendation systems.

For users working with LLM and inference in development and production environments, the De Novo GPU cloud offers AI Studio, a preconfigured environment for running and optimizing models. AI Studio offers ready-made container environments with support for CUDA, PyTorch, TensorRT, vector databases, and tools for RAG systems. Thanks to integrated APIs, developers can quickly deploy models on H200 without manually preparing the infrastructure, focusing directly on the product rather than on settings.
All computations take place in the secure De Novo cloud (ISO 27001, PCI DSS, CSI certified), which guarantees the legal purity of data. The new cards are fully compatible with popular tools (CUDA, PyTorch, Kubernetes), allowing developers to instantly gain performance gains without rebuilding their IT infrastructure. In short, H200 in the De Novo cloud is a tool that allows Ukrainian companies to enter a new era of multimodal and generative models and increase their competitiveness in the global AI market.