






Найсучасніші прискорювачі NVIDIA H200 доступні у хмарі De Novo
2025-12-16

De Novo оголошує про доступність для користувачів NVIDIA H200 — найпродуктивніших тензорних прискорювачів з обсягом пам'яті 141 ГБ, пропускною здатністю 4,8 ТБ/с та стековою пам’яттю HBM3e для великих мовних моделей (LLM). Це найсучасніше рішення для задач генеративного штучного інтелекту (GenAI), яке тепер доступне в українській хмарі.
Разом із прискорювачами NVIDIA H100, A100, L40S, L4, нові картки H200 формують наймасштабнішу GPU-інфраструктуру в країні, дозволяючи бізнесу навчати складні ШІ-моделі без передачі даних за кордон. Ключова перевага H200 — це не просто "більша потужність", а революційна підсистема із використанням високошвидкісної стекової пам’яті HBM3e. Раніше розвиток ШІ стримувала саме швидкість обміну даними, а не потужність процесорів. Нові карти усувають цей бар'єр, дозволяючи обробляти значно більші обсяги інформації для ШІ-моделей.
Технічні характеристики у цифрах
- Пропускна здатність підсистеми пам’яті: 4,8 ТБ/с (на 43% швидше за попередника H100).
- Обсяг пам’яті: 141 ГБ (на 76% більше, ніж у H100).
- Ефективність: Час обробки запитів (інференс) моделями рівня Llama 3 70B прискорюється до +50%.
Завдяки збільшеному обсягу пам'яті, великі мовні моделі (LLM) тепер можуть працювати на одній відеокарті без необхідності шардування (поділу задачу на частини), що значно підвищує швидкодію.

Новий високошвидкісний комунікаційний інтерфейс NVIDIA NVLink четвертого покоління, з пропускною здатністю до 900 ГБ/с, дозволяє об’єднувати до восьми прискорювачів H200 в єдиний обчислювальний вузел із загальним пулом пам'яті понад 1,1 ТБ. Це відкриває нові горизонти, дозволяючи українським компаніям вирішувати надскладні завдання.
Порівняння H200 з іншими моделями
Розробникам та AI-командам важливо чітко розуміти різницю між GPU-прискорювачами. Вибір залежить від задачі: генерація, інференс, fine-tuning, мультимодальні обчислення чи побудова RAG-систем. Ключові відмінності між H200 та іншими картками — у пропускній здатності пам’яті, обсязі HBM та можливості запуску моделей рівня Llama 3 70B без шардування. У той час як H100 — стандарт для LLM 2023 року, H200 уже оптимізовано під нове покоління моделей з довшим контекстом та вищою щільністю параметрів.
| Модель | Архітектура | Покоління тензорних ядер | Тип пам’яті | Обсяг пам’яті | Пропускна здатність пам’яті, макс. | NVLink | Версія PCIe | Оптимальний сценарій |
| H200 | Hopper | 4-е | HBM3 | 141 ГБ | 4,8 ТБ/с | 4.0 | 5.0 | LLM 70B+, RAG, мультимодальність |
| H100 | Hopper | 4-е | HBM3 | 80 ГБ | 3,35 ТБ/с | 4.0 | 5.0 | LLM 65B, тренування та інференс |
| A100 | Ampere | 3-є | HBM2e | 80 ГБ | 2 ТБ/с | 3.0 | 4.0 | навчання середніх моделей |
| L40S | Ada Lovelace | 4-е | GDDR6 | 48 ГБ | 864 ГБ/с | – | 4.0 | інференс у продуктиві |
| L4 | Ada Lovelace | 4-е | GDDR6 | 24 ГБ | 300 ГБ/с | – | 4.0 | легкий інференс, API |
Для задач генеративного ШІ з моделями понад 60 млрд параметрів, саме H200 забезпечує найбільшу продуктивність і гнучкість. Завдяки збільшеному обсягу HBM3e та прискоренню підсистеми пам'яті загалом, H200 дозволяє уникати шардування та виконувати повноцінний інференс «на одній картці». Це спрощує архітектуру застосунків, скорочує затримки (latency) та споживання енергії.
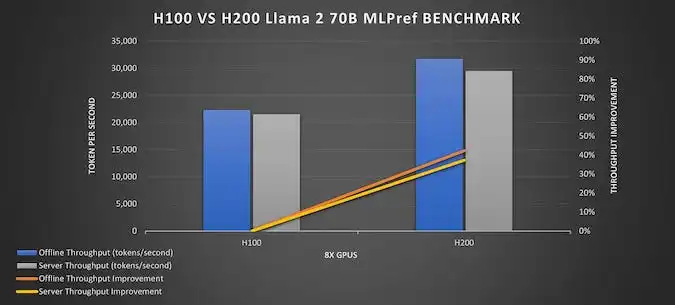
Cвоєю чергою, H100 залишається потужною опцією для точного налаштування та донавчання моделей (fine-tuning) або задач із меншим контекстом. L40S чи L4 — ефективні для високонавантажених inference‑сценаріїв у продуктивному середовищі, коли час відповіді критичний, але ресурси обмежені.
У хмарі De Novo усі ці карти доступні як окремо, так й у вигляді кластерів із NVLink (там, де ця технологія підтримується). Це дозволяє обирати оптимальну конфігурацію під кожен проєкт.
Ціна та доступність у хмарі De Novo
Прискорювачі NVIDIA H200 дозволяють інженерам та AI-командам отримати максимальну обчислювальну потужність без інвестицій у власну інфраструктуру. Ціна NVIDIA H200 у погодинній оренді становить $5,08 за повну потужність карту. Також доступні конфігурації оренди частини ресурсів:
- NVIDIA H200 NVL = $5,08/год;
- ½ NVIDIA H200 NVL = $2,54/год;
- ¼ NVIDIA H200 NVL = $1,27/год;
- ⅛ NVIDIA H200 NVL = $0,63/год.
Це дає змогу оптимізувати бюджети та обчислювальні ресурси під конкретні задачі та навантаження.
Де H200 підійдуть якнайкраще
У галузі генеративного AI (GenAI) H200 ідеально підходять для створення високоточних RAG-систем, які працюють із закритими корпоративними базами знань, наприклад, для автоматизації юридичного аналізу, обробки медичних даних або створення технічної документації. Також такі потужності критично важливі для навчання масштабних LLM з мільярдами параметрів та створення високопродуктивних чат-ботів чи рекомендаційних систем.

Для користувачів, які працюють із LLM та інференсом у середовищах розробки та продуктиву, у GPU хмарі De Novo доступна платформа AI Studio — передналаштоване середовище для запуску й оптимізації моделей. AI Studio пропонує готові контейнерні оточення з підтримкою CUDA, PyTorch, TensorRT, векторних баз даних та інструментів для RAG-систем. Завдяки інтегрованим API розробники можуть швидко розгортати моделі на H200 без ручної підготовки інфраструктури, зосередившись на безпосередньо на продукті, а не на налаштуваннях.
Усі обчислення відбуваються в захищеній хмарі De Novo (сертифікати ISO 27001, PCI DSS, КСЗІ), що гарантує юридичну чистоту даних. Нові карти повністю сумісні з популярними інструментами (CUDA, PyTorch, Kubernetes), що дозволяє розробникам миттєво отримати приріст продуктивності без перебудови IT-інфраструктури. Отже, H200 у хмарі De Novo — це інструмент, що дозволяє українським компаніям увійти в нову еру мультимодальних та генеративних моделей та підвищити конкурентоспроможність на глобальному ринку ШІ.