





Быстрее, точнее и без лишних тысяч в бюджете — как LLM помогает министерству проверять сметы
Это история о том, как искусственный интеллект помогает министерству проверять заявки на молодежные обмены: анализирует сметы, фильтрует размытые цели, выявляет необоснованные расходы и подсказывает, где стоит уточнить.

Система беспристрастна: поможет избежать ошибок, сформулировать идею четче — но и не позволит «случайно» заложить лишние десятки тысяч в бюджет. Вместо субъективного ручного рассмотрения — автоматическая проверка, подсказки в режиме реального времени, обоснованные замечания для должностных лиц.
Разработчики объяснили, как она работает на самом деле.
На конференции «ЯК ЦЕ ЗРОБЛЕНО. AI edition» был представлен опыт внедрения AI-модуля для анализа заявлений. Речь идет о системе, которая анализирует заявки на проекты международных молодежных обменов от Министерства молодежи и спорта — первый кейс внедрения генеративного ИИ в государственный сервис на базе платформы Diia.Engine.
Кейс представил Александр Акуленко, Head of AI в MK-Consulting, советник CEO Prozorro.Sale, руководитель группы разработки первой украинской платформы для ML-инженеров в De Novo.
Чтобы система действительно работала, команде пришлось вручную разбить заявки на блоки, сформировать серию запросов к LLM и обойти технические ограничения модели — в частности, короткое контекстное окно и отсутствие поддержки инструкций «из коробки». В итоге ИИ не просто анализирует текст, но и выдает релевантные и контекстно точные, по-человечески понятные замечания.
Какую проблему решали?
Министерство ежегодно проводит конкурсы проектов международных молодежных обменов с Польшей и Литвой. Это программа для некоммерческих организаций, работающих с молодежью. Заявители часто ошибаются при заполнении форм. Сотрудники министерства вручную проверяют заявки, что создает нагрузку и риск субъективной оценки. Целью было упростить процесс подачи заявок и их оценку.
Ключевые требования к AI-модели
- Автоматические рекомендации и подсказки при заполнении заявок.
- Генерация обоснованных замечаний для сотрудников.
- Уменьшение влияния человеческого фактора и риска ошибок при оценке заявок.
- Повышение качества заявок.
Решение построено как внешний интеграционный компонент к системе.
Обменов, которая создана на базе Diia.Engine. Весь процесс построен вокруг платформы Dify, которая отвечает за обработку запросов, интеграцию с LLM и возврат результатов.
Примеры обработки заявок
Простой кейс: краткое описание проекта
В базовом сценарии заявитель подает краткое описание проекта на украинском языке и выбирает приоритет из выпадающего списка. Разработчики настроили проверку соответствия описания проекта указанному приоритету с учетом заранее определенных логических правил.
В этом случае ИИ-модель автоматически подтвердила корректность ответа заявителя — цель проекта соответствовала выбранному приоритету. Замечаний не было, улучшений не требовалось.
Сложный кейс: анализ сметы
Команда MK-Consulting также реализовала автоматизированную проверку сложных заявлений с большим объемом информации, в частности — смет.
В примере одна из заявлений содержала расходы на экскурсии по Львову для 36 участников на сумму 36 000 грн. ШИ-модель, настроенная командой, определила, что эти расходы не имеют непосредственной связи с целями обмена.
В результате заявителю было дано рекомендация либо удалить эту строку из сметы, либо обосновать ее значимость в контексте заявленного проекта.
Типичные ошибки заявителей
Во время первых конкурсов команда MK-Consulting зафиксировала типичные слабые места в заявках:
- Расплывчатые формулировки цели.
- Отсутствие количественных показателей.
- Недостаточная детализация сметы.
Система, реализованная командой, автоматически выявляет подобные ошибки и дает релевантные рекомендации по улучшению.

Выбор технологического решения
Для реализации решения выбрали ИИ-модель Gemma 2. Решение построено как внешний интеграционный компонент к основной системе обмена, функционирующей на базе Diia.Engine для обработки запросов.
Оркестрация и инфраструктура
Для общей оркестрации работы ИИ-модели используется платформа для оркестрации приложений и моделей, которая является центральным узлом системы, управляющим всеми данными и их обработкой. Эта платформа развернута в Kubernetes с помощью Helm, принимает на вход данные от системы обмена и запускает определенные рабочие процессы (workflows) в Dify. Эти процессы могут включать шаги валидации, обработки данных, вызовы к LLM и другие операции. Это позволяет использовать комбинацию классической разработки и работы с генеративным ИИ или другими моделями в зависимости от потребностей бизнеса.
Под капотом используется PostgreSQL для хранения данных: конфигураций, истории запусков, данных приложений и т. д. Взаимодействие с SGLang обеспечивает работу с LLM, который используется для инференса. SGLang выступает как промежуточный слой между Dify и ИИ-моделью, предоставляя интерфейс для работы с LLM, обработки запросов, реализует батчинг, обработку нескольких запросов и управляет памятью GPU.
Выбор модели Gemma 2
Для обработки текста выбрана ИИ-модель Gemma 2, поскольку на момент начала работы с системой третья версия еще не была доступна. Gemma 2 с 27 миллиардами параметров показывала оптимальные результаты при обработке украинского языка и могла быть развернута в ресурсах заказчика. Для работы ИИ-модели необходимо минимум один GPU H100 или A100. Заказчик арендовал ресурсы у украинского провайдера облачных сервисов для искусственного интеллекта и машинного обучения.

Оптимизация работы модели
Изначально планировалось использовать комбинацию нескольких ИИ-моделей, поскольку Gemma хорошо работает с украинским языком, но имеет ограниченное контекстное окно. Идея заключалась в том, чтобы большой вывод передавать другой ИИ-модели, которая полноценно работает с контекстом, но не может нормально выдать результат на украинском языке. В конце планировалось обобщить все с помощью Gemma, чтобы заявитель и заказчик получили адекватный результат.
Однако в процессе удалось оптимизировать работу: разбить заявку на отдельные компактные блоки, которые анализируются изолированно, уменьшить объем нерелевантной информации, которую заполняет заявитель, чтобы она не влияла на работу ИИ-модели. В результате удалось получить нужный результат только с использованием Gemma без применения дополнительных ИИ-моделей, что сэкономило ресурсы для заказчика.
Технические вызовы и решения
При использовании SGLang для инференса возникли определенные ограничения: токенизатор для Gemma формально не поддерживал работу с системными инструкциями ИИ-модели. Это ограничивало настройки, в частности невозможность задать роль, стилистику ответов и т. д., что существенно влияло на качество ответов. Команде пришлось пересобрать SGLang вручную, обновить конфигурацию, что позволило использовать поддерживаемые системные промпты.
Настройка системы
Для настройки системы использовалась комбинация нескольких источников данных:
- Законодательство, регулирующее обмены, хотя оно было достаточно высокоуровневым и не давало ответов на все вопросы.
- Инструкции и личный опыт должностных лиц, занимающихся проверкой заявлений.
- Исторические данные: предыдущие заявления и результаты их рассмотрения, чтобы учесть это при настройке ИИ-модели.
По опыту Акуленко, фаза бизнес-анализа для подобных проектов иногда не менее, а может и более важна, чем в случае с классической разработкой. Большинство ИИ-моделей не специализированы, они не понимают, что происходит в голове эксперта, который оценивает заявление. Поэтому нужно детально понять, как думает эксперт, на что он опирается при оценке заявки, чтобы затем эту логику, насколько возможно, воспроизвести с помощью ИИ. На первой фазе требуются значительные инвестиции в бизнес-анализ, что часто не понимают заказчики, которые считают, что ИИ самостоятельно решит все задачи без предоставления необходимой информации.
Процесс обработки заявок
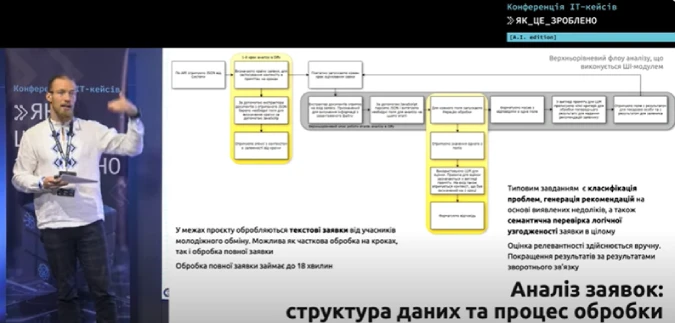
Процесс работает следующим образом:
- Получение через API JSON с полной информацией о заявке в Dify.
- Определение страны, к которой относится заявка, поскольку логика отличается для Польши и Литвы.
- Парсинг JSON, разбиение на отдельные логические блоки, отбрасывание нерелевантной информации.
- Для каждого поля, которое нужно учесть, отправляется отдельный запрос в Gemma или серия запросов, в зависимости от блока информации, с учетом предыдущего контекста и необходимых правил проверки.
- Сбор ответов, форматирование с помощью языковой модели, формирование отдельного ответа для заявителя и отдельного для должностного лица, поскольку ответы немного отличаются.
Контекстное окно Gemma ограничено 8192 токенами, а на обработку одного заявления уходит ориентировочно 100 000 токенов. Поэтому необходима комбинация шагов, чтобы не блокировать себя ограничениями контекстного окна и качественно обработать заявление.
Гибкость системы
Система не привязана к специфике работы конкретной ИИ-модели. В случае появления модели, которая лучше работает с украинским языком, работает быстрее или потребляет меньше ресурсов, можно без принципиальных изменений в системе переключиться на новую ИИ-модель.
Интерфейс для должностных лиц и заявителей
Команда также разработала интерфейс администратора, который позволяет:
- Просматривать пошаговое выполнение обработки заявки.
- Анализировать объем использованных токенов.
- Оценивать общее время выполнения.
Результаты анализа заявитель получает через тот же интерфейс, где подает заявки. Они включают оценку логической согласованности, рекомендации и возможность запуска частичного анализа на промежуточных этапах.
Кейсы

Мін’юст України створює AI-асистента, який відповідатиме на правові питання 24/7. Проєкт працюватиме на LLM у захищеній хмарі De Novo

«17 тыс. объектов вне учета» — До конца текущего года Украина планирует обновить Единый туристический реестр

AI для проверки строительных проектов: как «цифровой инспектор» анализирует документы, выявляет ошибки и автоматизирует процессы в государственном секторе Украины

Сервис «єДозвіл» получил ИИ-модуль, который автоматически проверяет документы, снимая рутину с чиновников

Уникальная модель может изменить мировую кардиодиагностику. Работая на биосенсорах и мощностях NVIDIA H100, система проводит диагностику за минуты вместо часов

Это история о том, как искусственный интеллект помогает министерству проверять заявки на молодежные обмены: анализирует сметы, фильтрует размытые цели, выявляет необоснованные расходы и подсказывает, где стоит уточнить

Посетили за вас конференцию по AI, и сейчас рассказываем историю о том, как покупка дешевой камеры едва не сорвала проект по внедрению computer vision на предприятии. И это не единственное, что пошло не так

Слишком большие поля, слишком мало агрономов, слишком переменчивая погода. Может ли искусственный интеллект быть ответом? Kernel внедряет 12 ML-моделей — от прогноза фаз роста до агрологистики — и показывает, как трансформировать агробизнес с помощью данных

Министерство молодежи и спорта Украины запустило первый в стране сервис на базе больших языковых моделей (LLM) на платформе Дія.Engine. Для размещения LLM использовали самое мощное в Украине оборудование

Каждая компания проходит свой путь «цифровой трансформации» и в каждом случае он уникальный. Особенно, если речь идет об организации национального масштаба

Успех агропромышленной компании сегодня во многом зависит от информационных технологий. Повысить урожайность, оптимизировать логистику, добиться глубокой автоматизации рутинных операций и обеспечить полную мобильность сотрудников — все это возможно благодаря эффективному применению ИТ

О том, как, работает «цифровая трансформация» на конкретных примерах в государстве мы поговорили с Евгением Ентисом — человеком, без участия которого трудно представить успех таких проектов национального масштаба как Prozorro и «Нова митниця»

Интервью с Андреем Бегуновым, директором департамента информационных технологий банка ПУМБ, который входит в ТОП-7 банков Украины по объемам активов (данные НБУ)