






NVIDIA H100: новый стандарт AI-вычислений
2025-11-18

NVIDIA H100 — это флагманский графический процессор для задач искусственного интеллекта, машинного обучения и HPC (High Performance Computing). Он построен на архитектуре Hopper, которая обеспечивает лучший прирост производительности по сравнению с предыдущим поколением A100.
Благодаря новым тензорным ядрам четвертого поколения, поддержке формата FP8 и интерфейсу NVLink 4.0, NVIDIA H100 (Tensor Core) открывает новую эру в сфере AI GPU — от обучения больших языковых моделей до вычислений уровня суперкомпьютеров. Это решение стало основой современных дата-центров и облачных платформ, включая De Novo.
Что такое NVIDIA H100 и чем она отличается от других моделей
NVIDIA H100 — это не просто очередное обновление линейки GPU. Это принципиально новый подход к вычислениям искусственного интеллекта, заложенный в архитектуре Hopper. По сравнению с A100 на базе Ampere новое поколение предлагает до четырехкратного роста производительности в задачах глубокого обучения и генеративного ИИ.
Ключевая особенность NVIDIA H100 — специализированные тензорные ядра четвертого поколения, поддерживающие вычисления в форматах FP8, FP16, TF32 и FP64. Благодаря этому GPU может эффективно работать как с обучением моделей, так и с инференсом, сохраняя баланс между точностью и скоростью. Интерфейс NVLink 4.0 обеспечивает пропускную способность более 900 ГБ/с (в обе стороны) между GPU, что позволяет масштабировать вычисления до уровня кластеров без потери производительности.
Еще одно важное преимущество — энергоэффективность. Несмотря на то, что H100 имеет TDP до 700 Вт, она демонстрирует лучшую производительность на ватт, чем предыдущее поколение, благодаря улучшенному контролю потоков данных и оптимизированной памяти HBM3. Это делает её идеальной для крупных дата-центров, работающих с моделями вроде GPT, Mistral или Llama.
Для сравнения: L40S предназначена преимущественно для генеративной графики и 3D-рендеринга, тогда как L4 — для видеоаналитики и стриминга. В свою очередь, H200 получила еще большую память HBM3e и повышенную пропускную способность, но сама архитектура Hopper остаётся сердцем всей линейки. Таким образом, NVIDIA H100 задает новый уровень для инфраструктуры искусственного интеллекта — от частных облаков и исследовательских лабораторий до национальных AI-кластеров.
Попробуйте: облако с NVIDIA GPU H200 / H100 / L40s / L4 / A100 NVL
Архитектура Hopper: что внутри нового поколения
Архитектура Hopper, на которой построена NVIDIA H100, стала крупнейшим технологическим скачком компании за последнее десятилетие. Это первая GPU-платформа, созданная специально для обучения больших языковых моделей (LLM), симуляций и высокопроизводительных научных вычислений.
В центре — обновленные тензорные ядра четвертого поколения, поддерживающие новый формат вычислений FP8. Этот режим позволяет значительно сократить объем передаваемых и сохраняемых данных без заметной потери точности, обеспечивая до четырех раз более высокую производительность по сравнению с A100 (на базе Ampere). Благодаря этому Hopper GPU H100 стал базовым выбором для развертывания трансформерных моделей с сотнями миллиардов параметров.
Еще одно нововведение — Tensor Memory Accelerator (TMA). Это аппаратный механизм, который снижает нагрузку на процессор при передаче данных между блоками памяти. Фактически, TMA позволяет GPU самостоятельно управлять потоками данных, что повышает эффективность при распределенном обучении больших моделей и снижает задержки. Отдельно стоит отметить поддержку DPX Instructions — специальных инструкций, оптимизированных для задач динамического программирования, включая биоинформатику, обработку графов и поиск оптимальных путей. Эти возможности делают NVIDIA H100 Tensor Core не только AI-ускорителем, но и универсальным процессором для HPC-нагрузок.
Подсистема памяти также претерпела изменения: HBM3 с пропускной способностью до 3 ТБ/с обеспечивает мгновенный доступ к данным и стабильную работу даже при сверхвысоких объемах параметров моделей. В сочетании с NVLink 4.0 и NVSwitch архитектура NVIDIA Hopper обеспечивает невиданный ранее уровень масштабирования внутри дата-центра — от одиночного GPU до кластеров из тысяч ускорителей. Таким образом, NVIDIA H100 сочетает вычислительную мощность, интеллектуальное управление памятью и масштабируемость, необходимую для новой эпохи NVIDIA AI.
Ключевые технические характеристики H100
NVIDIA H100 — это GPU, созданный для сред, где приоритетом являются масштабирование, стабильность и максимальная плотность вычислений. Каждый её компонент оптимизирован для работы с большими наборами данных, моделями глубокого обучения и симуляциями, которые продолжаются неделями без остановки.
Высокая плотность вычислений
В составе H100 — 16 896 CUDA-ядер и 528 тензорных ядер четвертого поколения. Формат смешанной точности FP8 позволяет эффективно использовать ресурсы памяти, сохраняя точность результатов при обучении больших языковых моделей. Благодаря этому GPU стабильно удерживает высокую производительность в многопоточных сценариях, характерных для трансформеров, генеративного ИИ и моделирования сложных физических процессов.
Память и пропускная способность
Видеопамять HBM3 объемом 80 ГБ обеспечивает пропускную способность до 3,35 ТБ/с. Это позволяет работать с массивами данных, которые превышают объем оперативной памяти обычных серверов. Вычисления не блокируются на передаче данных, а потоки выполняются без задержек, что критично для тренировки больших моделей или рендеринга сложных сцен.
Масштабирование через NVLink
Поддержка NVLink 4.0 обеспечивает обмен данными между несколькими GPU со скоростью 900 ГБ/с. Это открывает возможность строить кластеры, в которых несколько десятков ускорителей работают как единая система. Архитектура Hopper интегрирует этот механизм на аппаратном уровне, поэтому производительность масштабированных решений остается стабильной даже при многочасовых нагрузках.
Энергоэффективность и тепловая стабильность
TDP до 700 Вт компенсируется точным контролем энергопотребления и оптимизацией потоков данных. Система охлаждения SXM и новый контроллер памяти поддерживают стабильную работу даже в пиковых условиях дата-центров. Благодаря этому GPU демонстрирует высокую производительность на ватт и долгосрочную надежность в режиме непрерывной эксплуатации.
Обобщённые технические параметры.
- CUDA-ядра: 16 896
- Тензорные ядра: 528 (4-е поколение)
- Память: 80 ГБ HBM3
- Пропускная способность памяти: до 3 000 ГБ/с
- Интерфейс: PCIe 5.0 / SXM
- TDP: до 700 Вт
- NVLink 4.0: более 900 ГБ/с между GPU
- Форматы: FP8, FP16, TF32, FP64
Такие характеристики формируют базу для вычислительных кластеров, на которых работают современные модели искусственного интеллекта — от генеративных до научных.
Сравнение H100 vs A100 vs L40S vs L4
Линейка GPU от NVIDIA охватывает различные сценарии использования — от генеративного ИИ до видеоаналитики. H100 остаётся эталоном для задач обучения больших нейросетей, в то время как L40S, L4 и A100 формируют гибкий набор инструментов в интересах облачных сервисов и корпоративных дата-центров.
Модель | Архитектура | Поколение тензорных ядер | Тип памяти | Объем памяти | Пропускная способность памяти, макс. | Производительность (FP64 / FP32 / FP16 / FP8) TFLOPS** | NVLink | Версия PCIe |
| H100 | Hopper | 4-е | HBM3 | 80 ГБ | 3,35 ТБ/с | 34(67)/ 67-134*/ 1500 (3000)*/ 1900 (3958)* | 4.0 | 5.0 |
| A100 | Ampere | 3-е | HBM2e | 80 ГБ | 2 ТБ/с | 9,7 (19,5)*/ 19,5 (156)*/ 312-624*/ – | 3.0 | 4.0 |
| L40S | Ada Lovelace | 4-е | GDDR6 | 48 ГБ | 864 ГБ/с | 1,4 / 91,6 / 733 / 1466 | – | 4.0 |
| L4 | Ada Lovelace | 4-е | GDDR6 | 24 ГБ | 300 ГБ/с | – / 30,3 / 242 / 485 | – | 4.0 |
* С использованием структурной разреженности (sparsity 2:4).
** TFLOPS — тера операций в секунду.
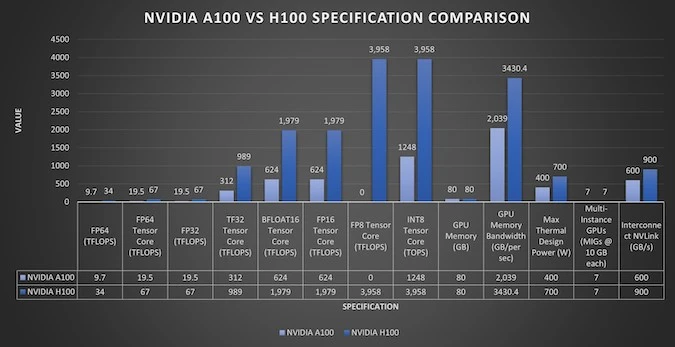
Архитектура Hopper, лежащая в основе GPU H100, использует память HBM3, поддерживает NVLink 4.0 и работает в режимах FP8/FP16/FP32/FP64, что обеспечивает высокую гибкость для AI-моделей. A100 (Ampere) остаётся надежным решением для традиционного машинного обучения, но в задачах генеративного ИИ NVIDIA H100 демонстрирует в 3–4 раза большую эффективность.
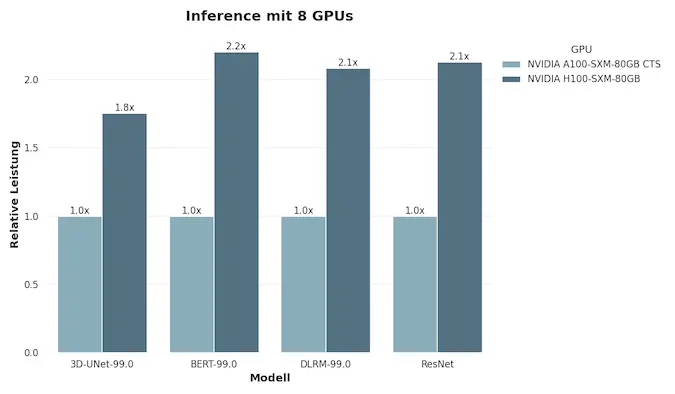
Модели L40S и L4 ориентированы на другие сценарии: первая подходит для 3D-рендеринга и генеративных визуальных моделей, вторая — для видеоаналитики, стриминга и оптимизации облачных медиасервисов. Вместе эти решения формируют целостную экосистему NVIDIA AI, где каждый GPU занимает своё место — от исследовательских лабораторий до промышленных дата-центров.
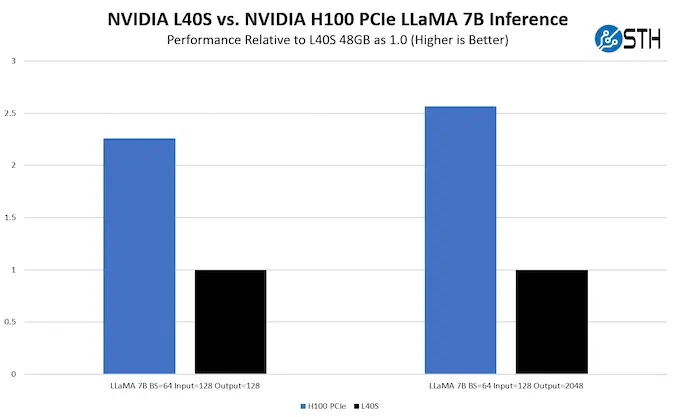
Ускорение нейронных сетей и LLM
Развитие больших языковых моделей требует колоссальной вычислительной мощности, и именно NVIDIA H100 стала базовым инструментом для этого класса задач. Благодаря архитектуре Hopper GPU выполняет до двух квадриллионов операций с плавающей запятой в секунду, обеспечивая оптимальное соотношение скорости и точности при обучении моделей объёмом более 175 миллиардов параметров. Ключевую роль играют тензорные ядра четвертого поколения. Они выполняют матричные операции в форматах FP8 и FP16, уменьшая объем передаваемых данных между блоками памяти и позволяя удерживать производительность даже в сложных топологиях кластеров. Вместе с Tensor Memory Accelerator это создает эффективный конвейер обработки, минимизирующий простои между этапами обучения нейронной сети.
Для больших языковых моделей, таких как GPT, Llama или Mistral, H100 NVIDIA Tensor Core GPU обеспечивает ускорение обучения в 3–4 раза по сравнению с предыдущим поколением. Поддержка режима Transformer Engine позволяет динамически менять точность вычислений, снижая энергопотребление без потери результативности. Это критично для дата-центров, где одновременно обучаются десятки моделей и каждый процент эффективности превращается в значительную экономию ресурсов. Благодаря архитектуре Hopper компании получают возможность строить полностью масштабируемые AI-платформы, где обучение, инференс и тестирование происходят в единой вычислительной среде. Такой подход сокращает время развертывания моделей и упрощает интеграцию инструментов для MLOps.
NVIDIA H100 сегодня используется в большинстве исследовательских и коммерческих кластеров для генеративного ИИ. Ее архитектура остаётся совместимой с фреймворками TensorFlow, PyTorch, JAX и Megatron, что позволяет быстро переносить модели между облаками и локальными средами. Именно эта универсальность делает NVIDIA H100 Tensor Core основой современных AI-решений — от нейронных ассистентов до систем научного моделирования.
Цена и доступность в облаке De Novo
NVIDIA H100 доступна в украинском облаке De Novo, что позволяет инженерам и исследователям получить вычислительную мощность мирового уровня без инвестиций в собственную инфраструктуру. Цена NVIDIA H100 в почасовой аренде составляет $3,65 за полную мощность карты. Также доступны конфигурации аренды части ресурсов:
- 1/2 H100 = $1,83/час;
- 1/4 H100 = $0,91/час;
- 1/8 H100 = $0,46/час.
Это позволяет оптимизировать бюджет и ресурсы под конкретную нагрузку.
Облачная инфраструктура De Novo построена с учетом стандартов ISO 27001, PCI DSS и КСЗИ, поэтому среда для H100 NVIDIA подходит как для обучения моделей, так и для их промышленного использования.
Высокая пропускная способность сети и поддержка NVLink 4.0 обеспечивают стабильную работу даже в сценариях с несколькими GPU, что особенно важно для масштабных LLM-проектов. По сравнению с покупкой оборудования аренда H100 GPU в облаке предоставляет несколько стратегических преимуществ. Компании могут быстро тестировать новые модели, не тратя время на развертывание железа, а затем масштабировать проекты, когда появляется стабильная нагрузка. Такой подход снижает затраты на энергопотребление, охлаждение и техническую поддержку, одновременно открывая доступ к самым современным GPU-архитектурам.
Сегодня NVIDIA AI-computing становится основой украинских облачных решений, и De Novo входит в число компаний, которые уже имеют самый полный парк GPU — A100, H100, L40S, L4 и даже новые H200. Это означает, что пользователи получают широкий выбор аппаратных профилей и могут запускать как легкие модели компьютерного зрения, так и полноценные трансформерные архитектуры. Для тех, кто рассматривает цену NVIDIA H100 как фактор выбора, облако De Novo позволяет оценить эффективность и масштабируемость без капитальных затрат. Это решение, сочетающее локальный суверенитет данных с возможностями глобального уровня — ключевое преимущество для компаний, развивающих собственные NVIDIA AI GPU-сервисы в Украине.
Платформа для работы с генеративным искусственным интеллектом - De Novo AI-STUDIO
GPU, который меняет стандарты AI
NVIDIA H100 определяет современную эпоху искусственного интеллекта. Этот ускоритель сформировал новый эталон вычислительной архитектуры — сочетание высокой пропускной способности, тензорных ядер четвертого поколения и гибкой масштабируемости. Именно эти параметры стали фундаментом технологий, на которых построен генеративный ИИ, большие языковые модели и симуляционные системы нового поколения. Украинским компаниям H100 открывает путь к созданию собственных AI-продуктов и исследовательских кластеров без зависимости от внешних провайдеров. Архитектура NVIDIA Hopper поддерживает новые форматы вычислений и обеспечивает стабильную интеграцию с существующими системами на базе A100, L40S и L4, формируя цельную экосистему GPU Hopper H100 для любых сценариев работы с данными.
Ближайшие годы станут этапом эволюции этой архитектуры — на рынке уже появляются ускорители H200 с памятью HBM3e и увеличенной пропускной способностью. Однако именно H100 остаётся проверенным стандартом для центров обработки данных, научных учреждений и AI-команд, стремящихся сочетать производительность, энергоэффективность и надёжность. Облачная инфраструктура De Novo, включающая H100, создаёт основу для масштабируемых AI-решений в Украине — от прототипов до промышленных систем. В этой модели ИИ становится не абстрактной технологией, а реальным инструментом развития экономики, науки и бизнеса. NVIDIA H100 — это не просто GPU. Это инженерный стандарт, задающий темп всей отрасли NVIDIA AI, определяя, каким будет следующее поколение интеллектуальных вычислений.