






NVIDIA H100: новий стандарт AI-обчислень
2025-11-18

NVIDIA H100 — це флагманський графічний процесор для задач штучного інтелекту, машинного навчання та HPC (High Perfirmance Computing). Він побудований на архітектурі Hopper, що забезпечує найкращий приріст продуктивності порівняно з попереднім поколінням A100.
Завдяки новим тензорним ядрам четвертого покоління, підтримці формату FP8 та інтерфейсу NVLink 4.0, NVIDIA H100 (Tensor Core) відкриває нову еру у сфері AI GPU — від навчання великих мовних моделей до розрахунків на рівні суперкомп’ютерів. Це рішення стало основою сучасних дата-центрів і хмарних платформ, включно з De Novo.
Що таке NVIDIA H100 та чим вона відрізняється від інших моделей
NVIDIA H100 — це не просто чергове оновлення лінійки GPU. Це принципово новий підхід до обчислень штучного інтелекту, закладений в архітектурі Hopper. Порівняно з A100 на базі Ampere, нове покоління пропонує до чотирьохразового зростання продуктивності у задачах глибокого навчання та генеративного AI.
Ключова особливість NVIDIA H100 — спеціалізовані тензорні ядра четвертого покоління, що підтримують обчислення у форматах FP8, FP16, TF32 і FP64. Завдяки цьому GPU може ефективно працювати як із навчанням моделей, так і з інференсом, зберігаючи баланс між точністю та швидкістю. Інтерфейс NVLink 4.0 забезпечує пропускну здатність понад 900 ГБ/с (в обидва боки) між GPU, що дозволяє масштабувати обчислення до рівня кластерів без втрат продуктивності.
Ще одна важлива перевага — енергоефективність. Хоча H100 має TDP до 700 Вт, вона демонструє кращу продуктивність на ват, ніж попереднє покоління, завдяки покращеному контролю потоків даних і оптимізованій пам’яті HBM3. Це робить її ідеальною для великих дата-центрів, які працюють із моделями на зразок GPT, Mistral чи Llama.
Для порівняння: L40S призначений переважно заради генеративної графіки та 3D-рендерингу, тоді як L4 — задля відеоаналітики та стрімінгу. У свою чергу, H200, отримала ще більшу пам’ять HBM3e і підвищену пропускну здатність, але сама архітектура Hopper залишається серцем усієї лінійки. Таким чином, NVIDIA H100 задає новий рівень щодо інфраструктури штучного інтелекту — від приватних хмар та дослідницьких лабораторій до національних AI-кластерів.
Спробуйте: хмара з NVIDIA GPU H200 / H100 / L40s / L4 / A100 NVL
Архітектура Hopper: що всередині нового покоління
Архітектура Hopper, на якій побудована NVIDIA H100, стала найбільшим технологічним стрибком компанії за останнє десятиліття. Це перша GPU-платформа, створена спеціально заради навчання великих мовних моделей (LLM), симуляцій і високопродуктивних наукових розрахунків.
У центрі — оновлені тензорні ядра четвертого покоління, що підтримують новий формат обчислень FP8. Цей режим дозволяє суттєво скоротити обсяг переданих і збережених даних без помітної втрати точності, забезпечуючи до чотирьох разів вищу продуктивність у порівнянні з A100 (на базі архітектури Ampere). Завдяки цьому Hopper GPU H100 став базовим вибором для розгортання трансформерних моделей із сотнями мільярдів параметрів.
Ще одне нововведення — Tensor Memory Accelerator (TMA). Це апаратний механізм, який зменшує навантаження на процесор під час передавання даних між блоками пам’яті. Фактично, TMA дозволяє GPU самостійно керувати потоками даних, що підвищує ефективність при розподіленому навчанні великих моделей і зменшує затримки. Окремо варто відзначити підтримку DPX Instructions — спеціальних інструкцій, оптимізованих в інтересах задач динамічного програмування, зокрема біоінформатики, обробки графів і пошуку оптимальних шляхів. Ці можливості роблять NVIDIA H100 Tensor Core не лише AI-прискорювачем, а й універсальним процесором для HPC-навантажень.
Підсистема пам’яті також зазнала змін: HBM3 із пропускною здатністю до 3 ТБ/с забезпечує миттєвий доступ до даних і стабільну роботу навіть при надвисоких обсягах параметрів моделей. У поєднанні з NVLink 4.0 і NVSwitch архітектура NVIDIA Hopperзабезпечує небачену до цього рівень масштабування в межах дата-центру — від одиночного GPU до кластерів із тисяч прискорювачів. Таким чином, NVIDIA H100 поєднує обчислювальну потужність, інтелектуальне керування пам’яттю та масштабованість, необхідну задля нової епохи NVIDIA AI.
Ключові технічні характеристики H100
NVIDIA H100 — це GPU, створений заради середовищ, де пріоритетом є масштабування, стабільність і максимальна щільність обчислень. Кожен її компонент оптимізовано для роботи з великими наборами даних, моделей глибокого навчання та симуляцій, які тривають тижнями без перерви.
Висока щільність обчислень
У складі H100 — 16 896 CUDA-ядер і 528 тензорних ядер четвертого покоління. Формат змішаної точності FP8 дозволяє ефективно використовувати ресурси пам’яті, зберігаючи точність результатів при навчанні великих мовних моделей. Завдяки цьому GPU стабільно утримує високу продуктивність у багатопоточних сценаріях, характерних для трансформерів, генеративного ШІ та моделювання складних фізичних процесів.
Пам’ять та пропускна здатність
Відеопам’ять HBM3 обсягом 80 ГБ забезпечує пропускну здатність до 3,35 ТБ/с. Це дозволяє працювати з масивами даних, які перевищують обсяг оперативної пам’яті звичайних серверів. Обчислення не блокуються на передачі даних, а потоки виконуються без затримок, що критично для тренування великих моделей або рендерингу складних сцен.
Масштабування через NVLink
Підтримка NVLink 4.0 забезпечує обмін даними між кількома GPU зі швидкістю 900 ГБ/с. Це відкриває можливість будувати кластери, у яких кілька десятків прискорювачів працюють як єдина система. Архітектура Hopper інтегрує цей механізм на апаратному рівні, тому продуктивність масштабованих рішень залишається стабільною навіть при багатогодинних навантаженнях.
Енергоефективність та теплова стабільність
TDP до 700 Вт компенсується точним контролем енергоспоживання та оптимізацією потоків даних. Система охолодження SXM і новий контролер пам’яті підтримують стабільну роботу навіть у пікових умовах дата-центрів. Завдяки цьому GPU демонструє високу продуктивність на ват й тривалу надійність у режимі безперервної експлуатації.
Узагальнені технічні параметри.
- CUDA-ядра: 16 896
- Тензорні ядра: 528 (4-е покоління)
- Пам’ять: 80 ГБ HBM3
- Пропускна здатність пам’яті: до 3 000 ГБ/с
- Інтерфейс: PCIe 5.0 / SXM
- TDP: до 700 Вт
- NVLink 4.0: понад 900 ГБ/с між GPU
- Формати: FP8, FP16, TF32, FP64
Такі характеристики формують базу для обчислювальних кластерів, на яких працюють сучасні моделі штучного інтелекту — від генеративних до наукових.
Порівняння H100 vs A100 vs L40S vs L4
Лінійка GPU від NVIDIA охоплює різні сценарії використання — від генеративного ШІ до відеоаналітики. H100 залишається еталоном задля задач навчання великих нейромереж, тоді як L40S, L4 та A100 формують гнучкий набір інструментів в інтересах хмарних сервісів і корпоративних дата-центрів.
Модель | Архітектура | Покоління тензорних ядер | Тип пам’яті | Обсяг пам’яті | Пропускна здатність пам’яті, макс. | Продуктивність (FP64 / FP32 / FP16 / FP8) TFLOPS** | NVLink | Версія PCIe |
| H100 | Hopper | 4-е | HBM3 | 80 ГБ | 3,35 ТБ/с | 34(67)/ 67-134*/ 1500 (3000)*/ 1900 (3958)* | 4.0 | 5.0 |
| A100 | Ampere | 3-є | HBM2e | 80 ГБ | 2 ТБ/с | 9,7 (19,5)*/ 19,5 (156)*/ 312-624*/ – | 3.0 | 4.0 |
| L40S | Ada Lovelace | 4-е | GDDR6 | 48 ГБ | 864 ГБ/с | 1,4 / 91,6 / 733 / 1466 | – | 4.0 |
| L4 | Ada Lovelace | 4-е | GDDR6 | 24 ГБ | 300 ГБ/с | – / 30,3 / 242 / 485 | – | 4.0 |
* З використанням структурної розрідженості (sparsity 2:4) у тензорних режимах.
** TFLOPS — теравиконань на секунду.
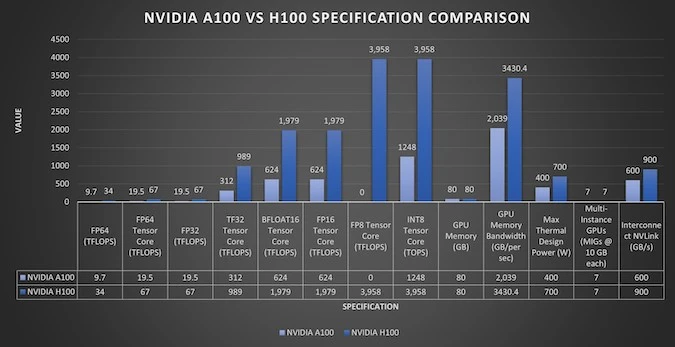
Архітектура Hopper, що покладена в основу GPU H100 використовує пам’ять HBM3, підтримує NVLink 4.0 та працює в режимах FP8/FP16/FP32/FP64, що забезпечує високу гнучкість для AI-моделей. A100 (Ampere) залишається надійним рішенням для традиційного машинного навчання, але в задачах генеративного ШІ NVIDIA H100 демонструє у 3–4 рази більшу ефективність.
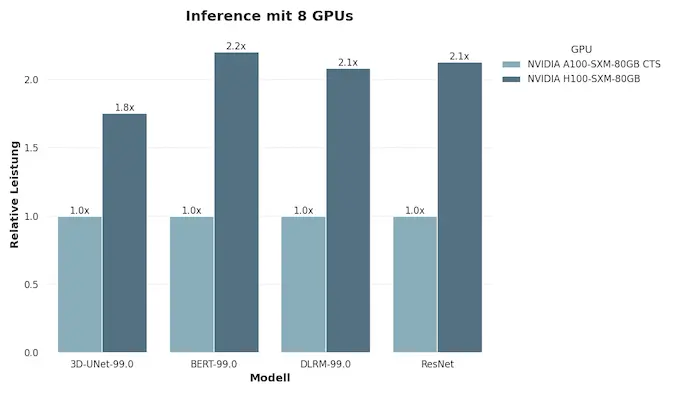
Моделі L40S та L4 орієнтовані на інші сценарії: перша підходить для 3D-рендерингу та генеративних візуальних моделей, друга — для відеоаналітики, стрімінгу та оптимізації хмарних медіасервісів. Разом ці рішення формують цілісну екосистему NVIDIA AI, де кожен GPU займає своє місце — від дослідницьких лабораторій до промислових дата-центрів.
Прискорення нейронних мереж та LLM
Розвиток великих мовних моделей вимагає колосальної обчислювальної потужності, і саме NVIDIA H100 став базовим інструментом задля цього класу задач. Завдяки архітектурі Hopper GPU виконує до двох квадрильйонів операцій з плаваючою комою за секунду, що забезпечує оптимальне співвідношення швидкості й точності при навчанні моделей з обсягом понад 175 мільярдів параметрів. Ключову роль відіграють тензорні ядра четвертого покоління. Вони виконують матричні операції у форматах FP8 і FP16, що зменшує обсяг переданих даних між блоками пам’яті та дозволяє утримувати продуктивність навіть у складних топологіях кластерів. Разом із Tensor Memory Accelerator це створює ефективний конвеєр обробки, який мінімізує простої між етапами навчання нейронної мережі.
В інтересах великих мовних моделей, таких як GPT, Llama або Mistral, H100 NVIDIA Tensor Core GPU забезпечує прискорення тренування у 3–4 рази порівняно з попереднім поколінням. Підтримка режиму Transformer Engine дозволяє динамічно змінювати точність обчислень, що знижує споживання енергії без втрати результативності. Це критично для дата-центрів, де одночасно навчаються десятки моделей і кожен відсоток ефективності перетворюється на значну економію ресурсів. Завдяки архітектурі Hopper GPU компанії отримують можливість будувати повністю масштабовані AI-платформи, у яких навчання, інференс і тестування відбуваються на єдиному обчислювальному середовищі. Такий підхід скорочує час розгортання моделей та полегшує інтеграцію інструментів для MLOps.
NVIDIA H100 сьогодні використовується в більшості дослідницьких й комерційних кластерів для генеративного AI. Її архітектура залишається сумісною з фреймворками TensorFlow, PyTorch, JAX і Megatron, що дозволяє швидко переносити моделі між хмарами й локальними середовищами. Саме ця універсальність робить NVIDIA H100 Tensor Core основою сучасних AI-рішень — від нейронних асистентів до систем наукового моделювання.
Ціна та доступність у хмарі De Novo
NVIDIA H100 доступна в українській хмарі De Novo, що дозволяє інженерам та дослідникам отримати обчислювальну потужність світового рівня без інвестицій у власну інфраструктуру.
Ціна NVIDIA H100 у погодинній оренді становить $3,65 за повну потужність карту. Також доступні конфігурації оренди частини ресурсів:
- 1/2 H100 = $1,83/год;
- 1/4 H100 = $0,91/год;
- 1/8 H100 = $0,46/год.
Це дає змогу оптимізувати бюджет та ресурси під конкретне навантаження.
Хмарна інфраструктура De Novo побудована з урахуванням стандартів ISO 27001, PCI DSS та КСЗІ, тому середовище задля H100 NVIDIA придатне як для навчання моделей, так й з метою їхнього промислового використання.
Висока пропускна здатність мережі та підтримка NVLink 4.0 забезпечують стабільну роботу навіть за сценаріїв з багатьма GPU, що особливо важливо для масштабних LLM-проєктів. У порівнянні з купівлею обладнання, оренда H100 GPU у хмарі надає кілька стратегічних переваг. Компанії можуть швидко тестувати нові моделі, не витрачаючи час на розгортання заліза, а потім масштабувати проєкти, коли з’являється стабільне навантаження. Такий підхід знижує витрати на енергоспоживання, охолодження та технічну підтримку, водночас відкриваючи доступ до найсучасніших GPU-архітектур.
Сьогодні NVIDIA AI-комп’ютинг стає основою українських хмарних рішень, і De Novo входить до переліку компаній, які вже мають найповніший парк GPU — A100, H100, L40S, L4 та навіть нові H200. Це означає, що користувачі отримують широкий вибір апаратних профілів і можуть запускати як легкі моделі комп’ютерного зору, так і повноцінні трансформерні архітектури. Заради тих, хто розглядає ціну NVIDIA H100 , як фактор вибору, хмара De Novo дає змогу оцінити ефективність та масштабованість без капітальних витрат. Це рішення, що поєднує локальний суверенітет даних із можливостями глобального рівня — ключова перевага для компаній, які розвивають власні NVIDIA AI GPU-сервіси в Україні.
Платформа для роботи з генеративним штучним інтелектом - De Novo AI-STUDIO
GPU, що змінює стандарти AI
NVIDIA H100 визначає сучасну епоху штучного інтелекту. Цей прискорювач сформував новий еталон обчислювальної архітектури — поєднання високої пропускної здатності, тензорних ядер четвертого покоління та гнучкої масштабованості. Саме ці параметри стали фундаментом в інтересах технологій, на яких побудовано генеративний ШІ, великі мовні моделі та симуляційні системи нового покоління. Українським компаніям H100 відкриває шлях до створення власних AI-продуктів і дослідницьких кластерів без залежності від зовнішніх провайдерів. Архітектура NVIDIA Hopper підтримує нові формати обчислень та забезпечує стабільну інтеграцію з існуючими системами на базі A100, L40S і L4, формуючи суцільну екосистему GPU Hopper H100 заради будь-яких сценаріїв роботи з даними.
Найближчі роки стануть етапом еволюції цієї архітектури — на ринку вже з’являються прискорювачі H200 із пам’яттю HBM3e та збільшеною пропускною здатністю. Проте саме H100 залишається перевіреним стандартом для центрів обробки даних, наукових установ і AI-команд, які прагнуть поєднати продуктивність, енергоефективність і надійність. Хмарна інфраструктура De Novo, що включає H100, створює основу для масштабованих AI-рішень в Україні — від прототипів до промислових систем. У цій моделі ШІ стає не абстрактною технологією, а реальним інструментом розвитку економіки, науки й бізнесу. NVIDIA H100 — це не просто GPU. Це інженерний стандарт, що задає темп усій галузі NVIDIA AI, визначаючи, яким буде наступне покоління інтелектуальних обчислень.