






NVIDIA H100: The New Standard in AI Computing
2025-11-18

NVIDIA H100 is a flagship graphics processor for artificial intelligence, machine learning, and high-performance computing (HPC) tasks. It is built on the Hopper architecture, which delivers the best performance gains compared to the previous-generation A100.
Equipped with fourth-generation Tensor Cores, FP8 support, and NVLink 4.0, NVIDIA H100 (Tensor Core) ushers in a new era in AI GPUs — from training large language models to supercomputer-level computing. This GPU has become a foundational element of modern data centers and cloud platforms, including De Novo.
What is NVIDIA H100 and how does it differ from other models?
NVIDIA H100 is not just another update to the GPU lineup. It is a fundamentally new approach to artificial intelligence computing, built on the Hopper architecture. Compared to the Ampere-based A100, the new generation delivers up to 4× higher performance in deep learning and generative AI workloads.
One of the defining features of the NVIDIA H100 is its fourth-generation Tensor Cores, which support computing in FP8, FP16, TF32, and FP64 formats. This allows the GPU to work effectively with both model training and inference, maintaining a balance between accuracy and speed. The NVLink 4.0 interface provides over 900 GB/s of bidirectional bandwidth between GPUs, allowing you to scale computing to the cluster level without sacrificing performance.
Another important advantage is energy efficiency. Although the H100 has a TDP of up to 700 W, it delivers better performance per watt than the previous generation thanks to improved data flow control and optimized HBM3 memory. This makes it ideal for large data centers working with models such as GPT, Mistral, or Llama.
For comparison, the L40S is designed primarily for generative graphics and 3D rendering, while the L4 is for video analytics and streaming. The H200, in turn, has even more HBM3e memory and increased bandwidth, but both GPUs are built on the Hopper architecture, which remains at the core of the entire lineup. Thus, the NVIDIA H100 sets a new standard for artificial intelligence infrastructure — from private clouds and research labs to national AI clusters.
Try it in the cloud with NVIDIA GPU H200 / H100 / L40s / L4 / A100 NVL
Hopper architecture: what's inside the new generation
The Hopper architecture, on which the NVIDIA H100 is built, is the company's biggest technological leap in the last decade. It is the first GPU platform designed specifically for training large language models (LLMs), simulations, and high-performance scientific computing.
At the heart of the architecture are updated fourth-generation Tensor Cores that support the new FP8 computing format. This mode significantly reduces the amount of data transferred and stored without noticeable loss of accuracy, delivering up to four times the performance of the A100 (based on the Ampere architecture). As a result, the Hopper GPU H100 has become the go-to choice for deploying transformer models with hundreds of billions of parameters.
Another innovation is the Tensor Memory Accelerator (TMA). It is a hardware mechanism that reduces CPU load on the processor when transferring data between memory blocks. In fact, TMA allows the GPU to independently manage data flows, which increases efficiency in the distributed training of large models and reduces latency. Hopper also introduces DPX Instructions — special instructions optimized for dynamic programming tasks, including bioinformatics, graph processing, and optimal path search. These capabilities make the NVIDIA H100 Tensor Core not only an AI accelerator but also a universal processor for HPC workloads.
The memory subsystem has also undergone changes: HBM3 with a bandwidth of up to 3 TB/s provides instant access to data and stable operation even with ultra-high model parameters. Combined with NVLink 4.0 and NVSwitch, the NVIDIA Hopper architecture delivers unprecedented levels of scalability within the data center, from a single GPU to clusters of thousands of accelerators. In this way, NVIDIA H100 combines the computing power, intelligent memory management, and scalability needed for the new era of NVIDIA AI.
Key technical specifications of the H100
NVIDIA H100 is a GPU designed for environments where scalability, stability, and maximum computing density are priorities. Every component is optimized to handle large data sets, deep learning models, and simulations that run for weeks without interruption.
High computing density
The H100 features 16,896 CUDA cores and 528 fourth-generation tensor cores. The FP8 mixed precision format allows for efficient use of memory resources while maintaining accuracy when training large language models. As a result, the GPU consistently maintains high performance in multi-threaded scenarios typical for transformers, generative AI, and complex physical process modeling.
Memory and bandwidth
80 GB of HBM3 video memory provides up to 3.35 TB/s of bandwidth. This allows you to work with data sets that exceed the RAM capacity of conventional servers. Computations are not blocked by data transfers, and streams are executed without delays, which is critical for training large models or rendering complex scenes.
Scaling via NVLink
NVLink 4.0 support enables data exchange between multiple GPUs at a speed of 900 GB/s. This opens up the possibility of building clusters in which several dozen accelerators work as a single system. The Hopper architecture integrates this mechanism at the hardware level, so the performance of scalable solutions remains stable even under heavy loads lasting many hours.
Energy efficiency and thermal stability
TDP up to 700 W is compensated by precise power consumption control and data flow optimization. The SXM cooling system and new memory controller support stable operation even in peak data center conditions. As a result, the GPU demonstrates high performance per watt and long-term reliability in continuous operation mode.
Summary of technical specifications.
- CUDA cores: 16,896
- Tensor cores: 528 (4th generation)
- Memory: 80 GB HBM3
- Memory bandwidth: up to 3,000 GB/s
- Interface: PCIe 5.0 / SXM
- TDP: up to 700 W
- NVLink 4.0: over 900 GB/s between GPUs
- Formats: FP8, FP16, TF32, FP64
These characteristics form the basis for computing clusters that run modern artificial intelligence models, from generative to scientific.
Comparison of H100 vs A100 vs L40S vs L4
NVIDIA's GPU lineup covers a variety of use cases, from generative AI to video analytics. The H100 remains the benchmark for large neural network training tasks, while the L40S, L4, and A100 form a flexible set of tools for cloud services and enterprise data centers.
Model | Architecture | Tensor core generation | Memory type | Memory capacity | Memory bandwidth, max. | FP64 / FP32 / FP16 / FP8 Performance (TFLOPS) | NVLink | PCIe version |
| H100 | Hopper | 4 | HBM3 | 80 GB | 3.35 TB/s | 34(67)/ 67-134*/ 1500 (3000)*/ 1900 (3958)* | 4.0 | 5 |
| A100 | Ampere | 3rd | HBM2e | 80 GB | 2 TB/s | 9.7 (19.5)*/ 19.5 (156)*/ 312-624*/ – | 3.0 | 4.0 |
| L40S | Ada Lovelace | 4 | GDDR6 | 48 GB | 864 GB/s | 1.4 / 91.6 / 733 / 1466 | – | 4.0 |
| L4 | Ada Lovelace | 4 | GDDR6 | 24 GB | 300 GB/s | – / 30.3 / 242 / 485 | – | 4.0 |
* Using 2:4 structural sparsity in tensor modes.
** TFLOPS — teraflops per second.
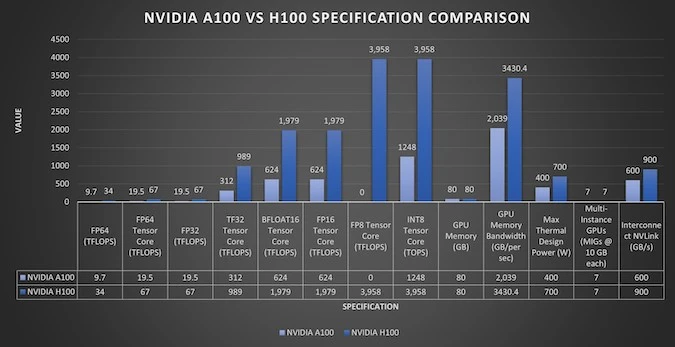
The Hopper architecture, which forms the basis of the H100 GPU, uses HBM3 memory, supports NVLink 4.0, and operates in FP8/FP16/FP32/FP64 modes, providing high flexibility for AI models. The A100 (Ampere) remains a reliable solution for traditional machine learning, but the NVIDIA H100 demonstrates 3-4 times greater efficiency in generative AI tasks.
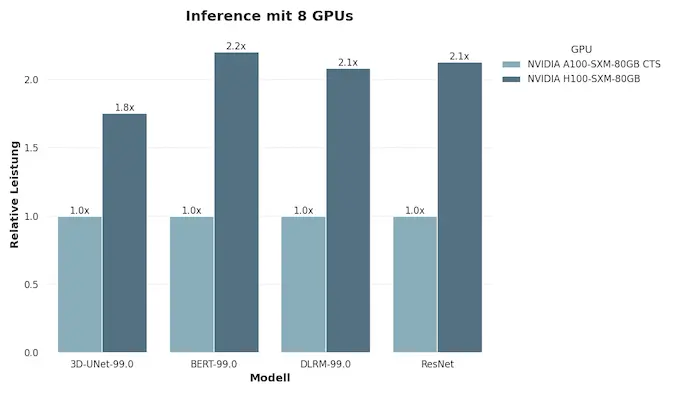
The L40S and L4 models are geared toward other scenarios: the former is suitable for 3D rendering and generative visual models, while the latter is suitable for video analytics, streaming, and optimization of cloud media services. Together, these solutions form a comprehensive NVIDIA AI ecosystem, where each GPU has its place — from research labs to industrial data centers.
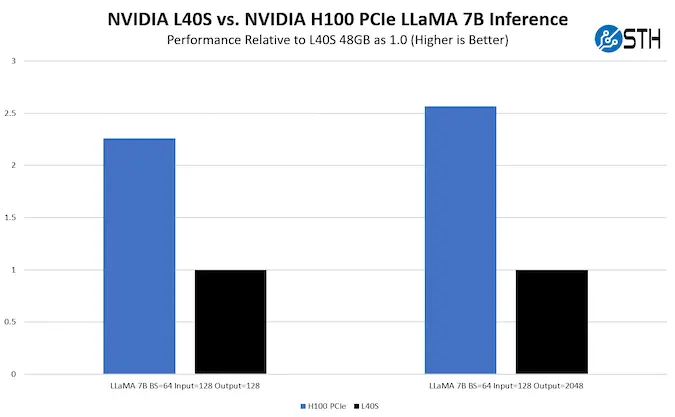
Accelerating neural networks and LLMs
The development of large language models requires enormous computing power, and it is the NVIDIA H100 that has become the basic tool for this class of tasks. Owing to the Hopper architecture, the GPU performs up to two quadrillion floating-point operations per second (≈2 PFLOPS), providing the optimal balance of speed and accuracy when training models with over 175 billion parameters. Fourth-generation tensor cores play a key role. They perform matrix operations in FP8 and FP16 formats, which reduces the amount of data transferred between memory blocks and maintains performance even in complex cluster topologies. Together with the Tensor Memory Accelerator, this creates an efficient processing pipeline that minimizes downtime between neural network training stages.
For large language models such as GPT, Llama, or Mistral, the NVIDIA H100 Tensor Core GPU provides 3-4x faster training acceleration compared to the previous generation. Support for Transformer Engine mode allows for dynamic changes in computational precision, reducing power consumption without sacrificing performance. This is critical for data centers, where dozens of models are trained simultaneously, and every percentage point of efficiency translates into significant resource savings. Thanks to the Hopper GPU architecture, companies can build fully scalable AI platforms where training, inference, and testing take place in a single computing environment. This approach reduces model deployment time and facilitates the integration of MLOps tools.
NVIDIA H100 is currently used in most research and commercial clusters for generative AI. Its architecture remains compatible with TensorFlow, PyTorch, JAX, and Megatron frameworks, allowing models to be quickly transferred between cloud and local environments. It is this versatility that makes NVIDIA H100 Tensor Core the foundation of modern AI solutions, from neural assistants to scientific modeling systems.
Price and availability in the De Novo cloud
NVIDIA H100 is available in the Ukrainian De Novo cloud, allowing engineers and researchers to access world-class computing power without investing in their own infrastructure.
The price of NVIDIA H100 on an hourly rental basis is $3.65 for full card power. Partial resource rental configurations are also available:
- 1/2 H100 = $1.83/hour;
- 1/4 H100 = $0.91/hour;
- 1/8 H100 = $0.46/hour.
This allows you to optimize your budget and resources for a specific workload.
De Novo's cloud infrastructure is built in accordance with ISO 27001, PCI DSS, and CIPS standards, making the environment for NVIDIA H100 suitable for both model training and industrial use.
High network throughput and NVLink 4.0 support ensure stable performance even in scenarios with multiple GPUs, which is especially important for large-scale LLM projects. Compared to purchasing hardware, renting H100 GPUs in the cloud offers several strategic advantages. Companies can quickly test new models without spending time deploying hardware, and then scale projects when a stable workload appears. This approach reduces energy consumption, cooling, and technical support costs while providing access to the most advanced GPU architectures.
Today, NVIDIA AI computing is becoming the foundation of Ukrainian cloud solutions, and De Novo is among the companies that already have the most complete fleet of GPUs — A100, H100, L40S, L4, and even the new H200. This means that users get a wide selection of hardware profiles and can run both lightweight computer vision models and full-fledged transformer architectures. For those who consider the price of NVIDIA H100 as a factor in their choice, the De Novo cloud allows them to evaluate performance and scalability without capital expenditure. This solution combines local data sovereignty with the scalability of global cloud systems — a key advantage for companies developing their own NVIDIA AI GPU services in Ukraine.
Platform for Generative AI — De Novo AI-STUDIO
A GPU that is changing AI standards
NVIDIA H100 defines the modern era of artificial intelligence. This accelerator has set a new benchmark for computing architecture — combining high throughput, fourth-generation tensor cores, and flexible scalability. These parameters have become the foundation for the technologies on which generative AI, large language models, and next-generation simulation systems are built. H100 opens the way for Ukrainian companies to create their own AI products and research clusters without dependence on external providers. The NVIDIA Hopper architecture supports new computing formats and provides stable integration with existing A100, L40S, and L4-based systems, forming a seamless Hopper H100 GPU ecosystem for any data processing scenario.
The coming years will be a period of evolution for this architecture, with H200 accelerators featuring HBM3e memory and increased bandwidth already appearing on the market. However, the H100 remains the proven standard for data centers, research institutions, and AI teams seeking to combine performance, energy efficiency, and reliability. De Novo's cloud infrastructure, which includes the H100, provides the foundation for scalable AI solutions in Ukraine — from prototypes to industrial systems. In this model, AI becomes not an abstract technology, but a real tool for the development of the economy, science, and business. NVIDIA H100 is more than a GPU. It is an engineering standard that sets the pace for the entire NVIDIA AI industry, defining what the next generation of intelligent computing will look like.