
Штучний інтелект на стероїдах
2024-03-19
Що таке тензорні ядра і яка роль хмарних сервісів, що пропонують доступ до сучасних GPU.
Технології штучного інтелекту (AI) та машинного навчання (ML) розвиваються вже десятиліття, проте лише останні декілька років вони зробили велетенський стрибок вперед. Цьому значною мірою сприяла і нова апаратна база, наприклад, доступність потужних GPU з тензорними ядрами. Такі пристрої можуть надати велику перевагу в процесі вирішення спеціалізованих завдань, таких як навчання або використання нейромереж, і сьогодні вони вже доступні як сервіс у хмарах українських операторів.
Що призвело до появи Tensor Processing Unit (TPU)
У сучасному ІТ-світі завдяки стрімкому розвитку технологій ситуація змінюється надзвичайно швидко і на передній план виходить вміння компаній своєчасно реагувати на ситуацію, використовуючи нову реальність на свою користь. Нещодавній стрибок у сфері AI/ML призвів до лавиноподібного зростання кількості нових продуктів, сервісів, а головне компаній, для яких штучний інтелект, машинне навчання, нейромережі та інші пов'язані з цим речі є основою бізнесу. Щодня з'являються сотні та тисячі стартапів, які використовують AI/ML для створення чогось нового, та й у повсякденному житті подібні технології оточують нас повсякчас.
Але, для ефективних обчислень AI/ML потрібні величезні ресурси, і донедавна це була серйозна проблема. Традиційні процесори (CPU) працюють надто повільно для таких завдань, де наріжним каменем є паралельна обробка та операції над числовими матрицями. Так, сучасні CPU містять десятки ядер, але цього все одно недостатньо, бо обчислення з їх застосуванням обходяться дорого, що є природною розплатою за універсальність.
На початку 2000-х виробники відеокарт дійшли висновку, що процес обробки графіки можна розбити на безліч невеликих підзадач, що виконуються паралельно. Причому вирішувати ці підзадачі можна на спеціалізованих ядрах, що працюють із шейдерами (інструкціями, які вказують, як правильно відображати та трансформувати об'єкти на зображеннях). Такі ядра мають досить обмежене застосування, але добре виконують операції над числами з плаваючою комою — те, що потрібно для графіки. Тим більше, що завдяки їхній відносній простоті та низькому енергоспоживанню, на одній відеокарті таких ядер може бути сотні та навіть тисячі.
Результатом об'єднання в одному пристрої універсальних процесорів, спеціалізованих шейдерних ядер та ряду інших технологій стала поява GPU (Graphics Processing Unit), які почали застосовувати не тільки для рендерингу зображень або роботи з відео. По суті, GPU стали універсальною відповіддю скрізь, де можлива масова паралельна обробка процесів. Їх почали застосовувати у наукових та інженерних завданнях, суперкомп'ютерних обчисленнях, при аналізі великих масивів даних та, зокрема, для AI/ML.
В останньому випадку, хоча швидкість роботи GPU була високою, виявилося, що великі моделі машинного навчання обраховуються все ж таки неприпустимо довго (якщо говорити про масове застосування). Що ж, є проблема – буде знайдено рішення. Відповіддю на виклик стала поява в 2017 році нового типу GPU на базі архітектури Volta, розробленої NVIDIA. Ключовим моментом тут стало те, що на додачу до шейдерних з'явилися ще й ядра нового типу – тензорні (Tensor Core) спеціально створені для виконання певних типів операцій. Це стало початком нового поштовху для ІТ-еволюції, наслідки якого ми зараз і спостерігаємо.
Зазначимо, що спеціальні тензорні модулі (Tensor Processing Unit, TPU) ще у 2016 році представила компанія Google, але вони використовувалися виключно для внутрішніх завдань і не з'являлися на масовому ринку.
Що таке тензорні ядра?
Що ж таке “тензорні ядра” і чому вони добре підходять для завдань AI/ML? Почнемо з того, що “тензор” це певний тип математичного об'єкта, який зазвичай виглядає як масив чисел певної розмірності. Наприклад, числова матриця — це тензор з розмірністю 2 (а “звичайне”, скалярне, число це теж тензор, але з розмірністю 0). Є й інші розмірності. Нам у цьому випадку важливо, що основна операція, у якій тензорні ядра забезпечують перевагу — це перемноження та складання числових матриць.
З таким завданням може впоратися і звичайний процесор (власне, раніше так і було), але для цього йому доведеться виконати велику кількість дій, використовувати безліч регістрів та навантажити кеш-пам'ять безліччю операцій читання/запису. Як наслідок, для ефективної роботи з тензорами будувалися величезні кластери, що містили сотні та тисячі CPU.
Разом з тим, тензорний процесор завдяки можливості одночасного виконання кількох обчислень, здійснить усі необхідні операції з перемноження матриць за один такт. До того ж у складі одного GPU можуть працювати сотні тензорних ядер, а отже, багато типових операцій виконуються паралельно, підвищуючи продуктивність.
«Тензорне ядро — дуже вузькоспеціалізований пристрій, все, що воно вміє — перемножити дві матриці 4х4 і скласти з третьою матрицею. Це завдання вимагає виконання 128 окремих операцій — 64 множення та 64 додавання. Магія в тому, що тензорне ядро робить все це за один такт, а типовий тензорний акселератор містить сотні тензорних ядер, що дозволяє йому працювати з цим типом навантаження в сотні і тисячі разів швидше за процесор загального призначення”. - Геннадій Карпов, директор з технологій De Novo.
Робота з числовими матрицями повсюдно зустрічається у процесі вирішення складних наукових, інженерних, логістичних завдань, а також, що важливо у контексті нашої статті, у машинному навчанні (ML). Основою ML є так зввані нейромережі — математичні моделі, що являють собою величезні масиви даних з "вузлів" та "з'єднань". Кожен вузол має певне значення, кожне з'єднання має "вагу" — коефіцієнт, що задає його важливість.
Для аналізу поведінки моделі необхідно кожне значення вузла нейромережі помножити на всі можливі ваги з'єднань. Фактично це завдання зводиться до перемноження матриць, а тут тензорні процесори показують приголомшливі результати. Тому сьогодні без них не обходиться фактично жодне серйозне завдання у сфері AI/ML і, відповідно, всі топові GPU містять тензорні ядра для підтримки обчислень.
Переваги, недоліки та основне застосування тензорних ядер
Серед ключових переваг GPU на тензорних ядрах можна назвати високу, недосяжну для інших технологій, продуктивність, особливо на специфічних завданнях, пов'язаних з алгоритмами штучного інтелекту, машинного або глибокого навчання (Deep Learning). Величезним плюсом є енергоефективність. Номінально, такі GPU споживають сотні ват, часом, до 700 Вт і більше, але питома витрата електроенергії — у перерахунку на кількість виконаних операцій — виявляється мінімальним. Також прискорювачі відносно легко поєднуються в кластери з можливістю майже безмежного масштабування.
Тензорні ядра, хоч і не є повною мірою універсальними, але, як ми зазначили вище, забезпечують суттєву перевагу в низці спеціалізованих завдань, що вимагають величезних обчислювальних навантажень. Особливо ефективні вони там, де завдання можуть бути розпаралелені та оптимізовані для тензорних обчислень.
Одним із типових застосувань тензорних ядер є тренування алгоритмів AI, пов'язаних, наприклад, з обробкою природної мови (NLP). При використанні звичайних GPU на шейдерних ядрах процес може зайняти тижні та місяці, а завдяки тензорним ядрам його нерідко можна скоротити до декількох днів. Крім того, забезпечується більш ефективна та швидка робота вже навченої нейромережі (інференс), оскільки тут важлива висока продуктивність та пропускна здатність у поєднанні з низькими затримками в процесі обробки та передачі даних.
Величезний приріст у продуктивності дають тензорні ядра і під час вирішення завдань високопродуктивних обчислень (High Performance Computing, HPC). Це може бути наукові чи складні інженерні завдання, моделювання, побудова прогнозів. Також ефективні такі GPU у проектах, пов'язаних віртуальною та доповненою реальністю, 3D-рендерингом, розробкою відеоігор.
Без тензорних ядер не вдалося б досягти рішучого прогресу в таких сферах, як швидке і точне розпізнавання (ідентифікація) осіб на зображеннях та відео, автономні автомобілі, машинний переклад, розробка ліків та дослідження в галузі ДНК. Сфера застосування технології розширюється щодня.
Проте, очевидним недолікам прискорювачів на тензорних ядрах залишається їхня висока ціна, яка для топових моделей може сягати десятків тисяч доларів. Та навіть з урахуванням цього фактору попит на них настільки великий, що від моменту оплати до фактичного постачання замовнику може сплинути до року. І це лише сама карта, до якої ще потрібна відповідна інфраструктура. Підсумкова вартість робочого рішення може легко сягнути $100 тис. та більше.
Тому, враховуючи потребу в обчислювальних потужностях для завдань AI/ ML з одного боку, і високу вартість відповідних апаратних компонентів з іншого — не дивно, що у світі швидко зростає попит на хмарні сервіси, що пропонують моментальний доступ до сучасних GPU на тензорних ядрах за моделлю як сервіс. Такі послуги вже доступні і від українських операторів.
Тензорні ядра українських операторів
Українські хмарні оператори вкладають чималі кошти у розвиток своїх ІТ-інфраструктур і загалом не відстають від глобальних тенденцій. Щоб отримати доступ до тензорних обчислювачів не обов'язково переносити свої дані за кордон — відповідні потужності є сьогодні й всередині нашої країни. Станом на початок 2024 року українські оператори пропонували доступ до GPU з тензорними ядрами на основі карт NVIDIA A40, A100 та H100. Кожна з цих моделей має свої особливості, переваги та сфери застосування. Щоб краще розібратися у цьому питанні розглянемо кожну модель детальніше.
Почнемо із серії “А”. Моделі А40 та А100 поєднує загальна процесорна архітектура — Ampere. Це архітектура третього покоління, представлена NVIDIA у 2020 році. Для її реалізації використовувалися найсучасніші на той момент техпроцеси — 7 та 8 нм, що дозволило розмістити на чіпі 54 млрд транзисторів. Також тут була реалізована підтримка фірмової, високошвидкісної технології інтерконнекту NVLink третього покоління, яка забезпечує швидкість обмінуданими між картами, що набагато швидше, ніж у випадку PCIe останнього покоління.
З цікавих технологій ще варто згадати NVIDIA Multi-Instance GPU. MIG дозволяє розділити один фізичний прискорювач на кілька, повністю ізольованих середовищ (інстансів) — кожне з власною пам'яттю, кешем та обчислювальними ядрами. Така функціональність може бути альтернативою гіпервізорній віртуалізації GPU. У порівнянні з архітектурою попереднього, другого покоління (називається Turing, з'явилася в 2018 році), моделі на основі Ampere використовують швидшу оперативну пам'ять, а також технології підвищеної надійності для забезпечення захисту та конфіденційності даних.
Тут ми коротко розглянемо дві моделі GPU серії A (скорочення від Ampere) — А40 та А100, тому що саме вони поряд з деякими іншими моделями сьогодні використовуються українськими хмарними операторами. При цьому в портфоліо NVIDIA, сьогодні, є десять основних моделей прискорювачів обчислень з тензорними ядрами, а також їх різноманітні варіації.
Як можна зробити висновок з назви, А40 є "молодшим" варіантом стосовно до А100 (мал. 1). Деякі порівняльні характеристики, що дають уявлення про різницю між моделями, представлені в таблиці.
Табл. 1. Порівняння окремих моделей GPU NVIDIA із тензорними ядрами
| Модель | A40 | A100 | H100 |
|---|---|---|---|
| Архітектура | Ampere | Ampere | Hooper |
| Техпроцес, нм | 8 | 7 | 4 |
| Шейдерні ядра (CUDA), од. | 10752 | 6912 | 16896 |
| Тензорні ядра, од. | 336 | 432 | 528 |
| Об'єм оперативної пам'яті, ГБ | 48 | 40/80 | 80/96 |
| Пропускна здатність пам'яті, ТБ/с | 0,7 | 2 | 3,35 |
| Інтерконнект, Гбіт/с | 112,5 | 600 | 900 |
| Продуктивність FP32* (non-Tensor), TFLOPS | 37,4 | 19,5 | 67 |
| Продуктивність TF32 (Tensor), TFLOPS | 149,6 | 312 | 989 |
| Основні завдання | VDI, хмарні ігри, аналіз даних, невеликі моделі AI/ML | Високопродуктивні обчислення, великі моделі AI/ML, аналіз величезних масивів даних | Високопродуктивні обчислення, навчання AI/ML для дуже складних моделей та наборів даних, аналіз величезних масивів даних, великомасштабні наукові симуляції |
| Орієнтовна ціна, $ тис. | 6 | 20 | 38 |
*Одинарна точність обчислень з плаваючою комою
Об'єктивно, А40 — це потужна, сучасна та продуктивна карта, яка разом з тим поступається А100 майже за всіма основними характеристиками, окрім, хіба що, кількості звичайних шейдерних ядер і, відповідно, може у деяких випадках мати вищу продуктивність на завданнях, що не потребують тензорних операцій. Також А40 коштує в рази дешевше. Коли ж мова заходить про сферу штучного інтелекту та машинного навчання, то тут А100 впевнено обходить молодшого брата. Кожна модель має власні сфери застосування.

Мал. 1. Внутрішній вигляд GPU NVIDIA A100
До типових завдань для А40 (мал. 2) можна віднести розгортання інфраструктур віртуальних робочих столів (VDI), хмарні ігри, аналіз бізнес-даних, НРС-навантаження невисокої інтенсивності, а також робота з невеликими моделями AI та ML. Для роботи з великими наборами даних або складними моделями AI/ML потужності не вистачить.

Мал. 2. GPU NVIDIA A40 у корпусі
Своєю чергою А100 була спеціально розроблена для високопродуктивних обчислень, роботи з великими моделями штучного інтелекту та машинного навчання, а також аналізу величезних масивів даних. Модель має більше тензорних ядер, оперативної пам'яті (яка до того ж працює набагато швидше), продуктивніший інтерконнект і ряд інших важливих переваг у порівнянні з А40 (мал. 3).
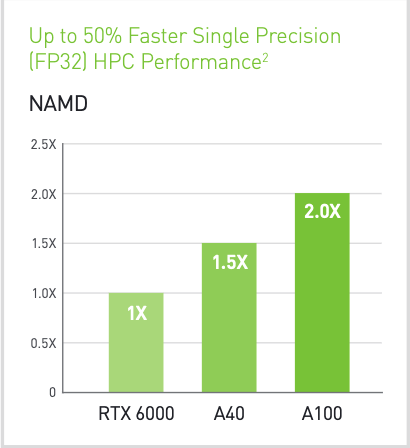
Мал. 3. Порівняння продуктивності GPU з тензорними ядрами A40 та A100 на HPC-завданнях. Джерело: NVIDIA.
З іншого боку, все це прямо впливає не лише на ціну, а й на енергоспоживання пристрою, накладаючи додаткові вимоги до розміщення та підтримки.
Технології не стоять на місці, в 2023 році NVIDIA представила індустрії нову архітектуру — Hooper та GPU серії "Н" на її основі. Тут вже використовується техпроцес 4 нм, що дозволило розмістити 80 млрд. транзисторів та суттєво збільшити кількість ядер. У поєднанні з новими технологіями (такими як Transformer Engine) це призвело до зростання продуктивності GPU в десятки разів на деяких завданнях AI/ML порівняно з моделями попередніх поколінь.
Швидкість інтерконекту завдяки технології NVLink четвертого покоління була збільшена в рази — до 900 Гбайт/с в обох напрямках (це в сім разів більше, ніж пропускна здатність шини PCIe Gen5). Крім того, NVLink тепер підтримує внутрішньомережеві обчислення (SHARP) і на завданнях ШІ здатна підтримувати обчислення екзафлопного рівня. Технологія MIG другого покоління забезпечує підтримку до семи ізольованих та захищених інстансів.
Додатково Hooper містить інструкції динамічного програмування DPX, які, якщо не вдаватися до подробиць, дозволяють ефективно та швидко вирішувати складні рекурсивні завдання шляхом їх розбиття на більш прості підзадачі. Як наслідок, наприклад, складні логістичні завдання вирішуються в рази швидше, ніж якби використовувалися GPU на Ampere.
Найпотужнішою GPU NVIDIA на основі архітектури Hooper, станом на 1 квартал 2024 року, є модель Н100 (мал. 4). У неї більше ядер (як шейдерних, так і тензорних), оперативної пам'яті та обчислювальної потужності, ніж у будь-якої системи серії А.

Мал. 4. Внутрішній вигляд GPU NVIDIA Н100.
Швидше працює оперативна пам'ять, збільшено пропускну здатність інтерконнекту, помітно зросла продуктивність на будь-яких завданнях. Н100 відмінно справляється з інтенсивними обчисленнями, навчанням великих і складних моделей AI/ML, великомасштабними науковими симуляціями, обробкою великих масивів даних і т.д.
Одним із важливих технологічних нововведень, які з'явилися в рамках архітектури Hooper, є підтримка двох нових форматів точності обчислень із плаваючою комою – FP8 та FT32.
Нагадаємо, не вдаючись до подробиць, що сьогодні існує ціла низка подібних форматів. Найбільш ресурсомісткий – FP64 або обчислення подвійної точності, він використовується в наукових завданнях, при складному проектуванні та майже не використовується в інших сферах. Найпоширеніший – FP32, що забезпечує одинарну точність. При цьому на завданнях AI/ML, наприклад, під час навчання нейромереж, точність обчислень далеко не завжди є критичною, на відміну від часу виконання завдання, тому тут поширений формат FP16 (з половинною точністю).
У NVIDIA пішли ще далі, застосувавши в нових GPU формат FP8, що вимагає ще менше обчислювальних ресурсів, ніж навіть FP16 і, відповідно, скорочує час обробки завдання. За даними NVIDIA, обчислення у форматі FP8 на архітектурі Hopper виконуються у 6 разів швидше, ніж аналогічні завдання у FP16 на Ampere. Ба більше, тензорні ядра Hopper здатні комбінувати формати FP8 та FP16, що дозволяє суттєво прискорити процес навчання деяких типів нейронних мереж без втрати точності.
Також доданий новий фірмовий формат FT32, що є чимось середнім між звичними обчисленнями одинарної і половинної точності. За даними NVIDIA, це дає точність близьку до FP32 та швидкість FP16. Завдяки чому обробка задач AI/ML відбувається втричі швидше, у порівнянні з тензорними ядрами Ampere.
Але, знову-таки, наслідком підвищеної продуктивності та ефективності є висока ціна пристрою. До того ж, через зростання кількості робочих навантажень AI/ML, попит на H100 сьогодні відчутно перевищує пропозицію. У підсумку, ціна одного лише прискорювача легко може перевищити $40 тис, отже покупка такого GPU далеко не всім по кишені.
Натомість доступ до нього можна отримати з хмари De Novo, з новими сервісами Hosted Tensor Infrastructure (HTI) та Tensor Cloud на базі приватної та колективної хмари відповідно. Або у складі першої національної AI/ML-платформи ML Cloud. Сьогодні De Novo це єдиний український хмарний оператор, який пропонує доступ до найпотужніших GPU NVIDIA H100, фізично розміщених всередині країни.
Нові GPU на тензорних ядрах є потужними інструментами роботи з алгоритмами машинного навчання, штучного інтелекту та інших завдань, які потребують високої продуктивності. Проте, перед використанням пристроїв необхідно ретельно оцінити майбутні завдання та вибрати систему з відповідними характеристиками.
Яке рішення підійде саме вам легко перевірити на практиці. Достатньо звернутися до спеціалістів De Novo, які нададуть розгорнуту консультацію з будь-яких технічних питань. Потім можна отримати тестовий доступ до необхідного сервісу або навіть запустити пілотний проект, після чого, якщо все влаштовує, перейти до повноцінної експлуатації, отримуючи всі переваги передових технологій.